Прозрачность системы это
Прозрачность, открытость и масштабируемость в распределённой системе
Прозрачность.
Важная задача распределенных систем состоит в том, чтобы скрыть тот факт, что процессы и ресурсы физически распределены по множеству компьютеров. Распределенные системы, которые представляются пользователям и приложениям в виде единой компьютерной системы, называются прозрачными (transparent).
Концепция прозрачности, как видно из табл. 1.1, применима к различным аспектам распределенных систем.
Таблица 1.1. Различные формы прозрачности в распределенных системах
Прозрачность
Описание
Скрывается разница в представлении данных и доступе к ресурсам
Скрывается местоположение ресурса
Скрывается факт перемещения ресурса в другое место
Скрывается факт перемещения ресурса в процессе обработки в другое место
Скрывается факт репликации ресурса
Скрывается факт возможного совместного использования ресурса несколькими конкурирующими пользователями
Скрывается отказ и восстановление ресурса
Скрывается, хранится ресурс (программный) на диске или находится в оперативной памяти
Прозрачность доступа (access transparency) Например, распределенная система может содержать компьютеры с различными операционными системами, каждая из которых имеет собственные ограничения на способ представления имен файлов. Разница в ограничениях на способ представления имен файлов, так же как и собственно работа с ними, должны быть скрыты от пользователей и приложений.
Прозрачность местоположения (location transparency) Так, прозрачность местоположения может быть достигнута путем присвоения ресурсам только логических имен, то есть таких имен, в которых не содержится закодированных сведений о местоположении ресурса (URL)
О распределенных системах, в которых смена местоположения ресурсов не влияет на доступ к ним, говорят как об обеспечивающих прозрачность переноса (mig-ration transparency).
Более серьезна ситуация, когда местоположение ресурсов может измениться в процессе их использования, причем пользователь или приложение ничего не заметят. В этом случае говорят, что система поддерживает прозрачность смены местоположения (relocation transparency). Примером могут служить мобильные пользователи, работающие с беспроводным переносным компьютером и не отличающиеся (даже временно) от сети при перемещении с места на место.
Прозрачность репликации (replication transparency) позволяет скрыть тот факт, что существует несколько копий ресурса. Для скрытия факта репликации от пользователей необходимо, чтобы все реплики имели одно и то же имя. Соответственно, система, которая поддерживает прозрачность репликации, должна поддерживать и прозрачность местоположения, поскольку иначе невозможно будет обращаться к репликам без указания их истинного местоположения.
Например, два независимых пользователя могут сохранять свои файлы на одном файловом сервере или работать с одной и той же таблицей в совместно используемой базе данных. Следует отметить, что в таких случаях ни один из пользователей не имеет никакого понятия о том, что тот же ресурс задействован другим пользователем. Это явление называется прозрачностью параллельного доступа (concurrency transparency). Отметим, что подобный параллельный доступ к совместно используемому ресурсу сохраняет этот ресурс в непротиворечивом состоянии.
Прозрачность отказов (failure transparency) означает, что пользователя никогда не уведомляют о том, что ресурс (о котором он мог никогда и не слышать) не в состоянии правильно работать и что система далее восстановилась после этого повреждения. Маскировка сбоев — это одна из сложнейших проблем в распределенных системах и столь же необходимая их часть. Основная трудность состоит в маскировке проблем, возникающих в связи с невозможностью отличить неработоспособные ресурсы от ресурсов с очень медленным доступом.
Последний тип прозрачности, который обычно ассоциируется с распределенными системами, — это прозрачность сохранности (persistence transparency), маскирующая реальную (диск) или виртуальную (оперативная память) сохранность ресурсов. Так, например, многие объектно-ориентированные базы данных предоставляют возможность непосредственного вызова методов для сохраненных объектов. За сценой в этот момент происходит следующее: сервер баз данных сначала копирует состояние объекта с диска в оперативную память, затем выполняет операцию и, наконец, записывает состояние на устройство длительного хранения. Пользователь, однако, остается в неведении о том, что сервер перемещает данные между оперативной памятью и диском. Сохранность играет важную роль в распределенных системах, однако не менее важна она и для обычных (не распределенных) систем.
Достижение прозрачности распределения — это разумная цель при проектировании и разработке распределенных систем, но она не должна рассматриваться в отрыве от других характеристик системы, например производительности.
Другая важная характеристика распределенных систем — это открытость. Открытая распределенная система (open distributed system) — это система, предлагающая службы, вызов которых требует стандартные синтаксис и семантику. Например, в компьютерных сетях формат, содержимое и смысл посылаемых и принимаемых сообщений подчиняются типовым правилам. Эти правила формализованы в протоколах. В распределенных системах службы обычно определяются через интерфейсы (interfaces), которые часто описываются при помощи языка определения интерфейсов (Interface Definition Language , IDL). Описание интерфейса на IDL почти исключительно касается синтаксиса служб, оно точно отражает имена доступных функций, типы параметров, возвращаемых значений.
Будучи правильно описанным, определение интерфейса допускает возможность совместной работы произвольного процесса, нуждающегося в таком интерфейсе, с другим произвольным процессом, предоставляющим этот интерфейс, также позволяет двум независимым группам создать абсолютно разные реализации этого интерфейса для двух различных распределенных систем, которые будут работать абсолютно одинаково. переносимости и способности к взаимодействию. Способность к взаимодействию (interoperability) характеризует, насколько две реализации систем или компонентов от разных производителей в состоянии совместно работать, полагаясь только на то, что службы каждой из них соответствуют общему стандарту. Переносимость (portability) характеризует то, насколько приложение, разработанное для распределенной системы А, может без изменений выполняться в распределенной системе В, реализуя те же, что и в А интерфейсы.
Следующая важная характеристика открытых распределенных систем — это гибкость. Под гибкостью мы понимаем легкость конфигурирования системы, состоящей из различных компонентов, возможно от разных производителей. Недолжны вызывать затруднений добавление к системе новых компонентов или замена существующих, при этом прочие компоненты, с которыми не производилось никаких действий, должны оставаться неизменными. Другими словами, открытая распределенная система должна быть расширяемой. Например, к гибкой системе должно быть, относительно несложно добавить части, работающие под управлением другой операционной системы, или даже заменить всю файловую систему целиком. Насколько всем нам знакома сегодняшняя реальность, говорить о гибкости куда проще, чем ее осуществить.
Масштабируемость
Масштабируемость — это одна из наиболее важных задач при проектировании распределенных систем. Масштабируемость системы может измеряться по трем различным показателям. Во-первых, система может быть масштабируемой по отношению к ее размеру, что означает легкость подключения к ней дополнительных пользователей и ресурсов. Во-вторых, система может масштабироваться географически, то есть пользователи и ресурсы могут быть разнесены в пространстве. В-третьих, система может быть масштабируемой в административном смысле, то есть быть проста в управлении при работе во множестве административно независимых организаций. К сожалению, система, обладающая масштабируемостью по одному или нескольким из этих параметров, при масштабировании часто дает потерю производительности.
Проблемы масштабируемости
Если система нуждается в масштабировании, необходимо решить множество разнообразных проблем. Сначала рассмотрим масштабирование по размеру. Проблемы такой схемы очевидны: при увеличении числа пользователей сервер легко может стать узким местом системы. Даже если мы обладаем фактически неограниченным запасом по мощности обработки и хранения данных, ресурсы связи с этим сервером, в конце концов, будут исчерпаны и не позволят нам расти дальше.
Таблица 1.2. Примеры ограничений масштабируемости
Прозрачность
Прозрачность (transparency) сети достигается в том случае, когда сеть представляется пользователям не как множество отдельных компьютеров, связанных между собой сложной системой кабелей, а как единая традиционная вычислительная машина с системой разделения времени. Известный лозунг компании Sun Microsystems: «Сеть — это компьютер» — говорит именно о такой прозрачной сети.
Прозрачность может быть достигнута на двух различных уровнях — на уровне пользователя и на уровне программиста. На уровне пользователя прозрачность означает, что для работы с удаленными ресурсами он использует те же команды и привычные ему процедуры, что и для работы с локальными ресурсами. На программном уровне прозрачность заключается в том, что приложению для доступа к удаленным ресурсам требуются те же вызовы, что и для доступа к локальным ресурсам. Прозрачность на уровне пользователя достигается проще, так как все особенности процедур, связанные с распределенным характером системы, маскируются от пользователя программистом, который создает приложение. Прозрачность на уровне приложения требует сокрытия всех деталей распределенности средствами сетевой операционной системы.
Сеть должна скрывать все особенности операционных систем и различия в типах компьютеров. Пользователь компьютера Macintosh должен иметь возможность обращаться к ресурсам, поддерживаемым UNIX-системой, а пользователь UNIX должен иметь возможность разделять информацию с пользователями Windows NT. Подавляющее число пользователей ничего не хочет знать о внутренних форматах файлов или о синтаксисе команд UNIX. Пользователь терминала IBM 3270 должен иметь возможность обмениваться сообщениями с пользователями сети персональных компьютеров без необходимости вникать в секреты трудно запоминаемых адресов.
Концепция прозрачности может быть применена к различным аспектам сети. Например, прозрачность расположения означает, что от пользователя не требуется знаний о месте расположения программных и аппаратных ресурсов, таких как процессоры, принтеры, файлы и базы данных. Имя ресурса не должно включать информацию о месте его расположения, поэтому имена типа mashinel:prog.c или \ftp_servpub прозрачными не являются. Аналогично, прозрачность перемещения означает, что ресурсы должны свободно перемещаться из одного компьютера в другой без изменения своих имен. Еще одним из возможных аспектов прозрачности является прозрачность параллелизма, заключающаяся в том, что процесс распараллеливания вычислений происходит автоматически, без участия программиста, при этом система сама распределяет параллельные ветви приложения по процессорам и компьютерам сети. В настоящее время нельзя сказать, что свойство прозрачности в полной мере присуще многим вычислительным сетям, это скорее цель, к которой стремятся разработчики современных сетей.
4.4 Поддержка разных видов трафика
Компьютерные сети изначально предназначены для совместного доступа пользователя к ресурсам компьютеров: файлам, принтерам и т. п. Трафик, создаваемый этими традиционными службами компьютерных сетей, имеет свои особенности и существенно отличается от трафика сообщений в телефонных сетях или, например, в сетях кабельного телевидения. Однако 90-е годы стали годами проникновения в компьютерные сети графика мультимедийных данных, представляющих в цифровой форме речь и видеоизображение. Компьютерные сети стали использоваться для организации видеоконференций, обучения и развлечения на основе видеофильмов и т. п. Естественно, что для динамической передачи мультимедийного графика требуются иные алгоритмы и протоколы и, соответственно, другое оборудование.
Главной особенностью трафика, образующегося при динамической передаче голоса или изображения, является наличие жестких требований к синхронности передаваемых сообщений. Для качественного воспроизведения непрерывных процессов, которыми являются звуковые колебания или изменения интенсивности света в видеоизображении, необходимо получение измеренных и закодированных амплитуд сигналов с той же частотой, с которой они были измерены на передающей стороне. При запаздывании сообщений будут наблюдаться искажения.
В то же время трафик компьютерных данных характеризуется крайне неравномерной интенсивностью поступления сообщений в сеть при отсутствии жестких требований к синхронности доставки этих сообщений. Например, доступ пользователя, работающего с текстом на удаленном диске, порождает случайный поток сообщений между удаленным и локальным компьютерами, зависящий от действий пользователя по редактированию текста, причем задержки при доставке в определенных (и достаточно широких с компьютерной точки зрения) пределах мало влияют на качество обслуживания пользователя сети. Все алгоритмы компьютерной связи, соответствующие протоколы и коммуникационное оборудование были рассчитаны именно на такой «пульсирующий» характер трафика, поэтому необходимость передавать мультимедийный трафик требует внесения принципиальных изменений как в протоколы, так и оборудование. Сегодня практически все новые протоколы в той или иной степени предоставляют поддержку мультимедийного графика.
Особую сложность представляет совмещение в одной сети традиционного компьютерного и мультимедийного трафика. Передача исключительно мультимедийного трафика компьютерной сетью хотя и связана с определенными сложностями, но вызывает меньшие трудности. А вот случай сосуществования двух типов трафика с противоположными требованиями к качеству обслуживания является намного более сложной задачей. Обычно протоколы и оборудование компьютерных сетей относят мультимедийный трафик к факультативному, поэтому качество его обслуживания оставляет желать лучшего. Сегодня затрачиваются большие усилия по созданию сетей, которые не ущемляют интересы одного из типов графика. Наиболее близки к этой цели сети на основе технологии ATM, разработчики которой изначально учитывали случай сосуществования разных типов графика в одной сети.
Управляемость сети подразумевает возможность централизованно контролировать состояние основных элементов сети, выявлять и разрешать проблемы, возникающие при работе сети, выполнять анализ производительности и планировать развитие сети. В идеале средства управления сетями представляют собой систему, осуществляющую наблюдение, контроль и управление каждым элементом сети — от простейших до самых сложных устройств, при этом такая система рассматривает сеть как единое целое, а не как разрозненный набор отдельных устройств.
Хорошая система управления наблюдает за сетью и, обнаружив проблему, активизирует определенное действие, исправляет ситуацию и уведомляет администратора о том, что произошло и какие шаги предприняты. Одновременно с этим система управления должна накапливать данные, на основании которых можно планировать развитие сети. Наконец, система управления должна быть независима от производителя и обладать удобным интерфейсом, позволяющим выполнять все действия с одной консоли.
Решая тактические задачи, администраторы и технический персонал сталкиваются с ежедневными проблемами обеспечения работоспособности сети. Эти задачи требуют быстрого решения, обслуживающий сеть персонал должен оперативно реагировать на сообщения о неисправностях, поступающих от пользователей или автоматических средств управления сетью. Постепенно становятся заметны более общие проблемы производительности, конфигурирования сети, обработки сбоев и безопасности данных, требующие стратегического подхода, то есть планирования сети. Планирование, кроме этого, включает прогноз изменений требований пользователей к сети, вопросы применения новых приложений, новых сетевых технологий и т. п.
Полезность системы управления особенно ярко проявляется в больших сетях: корпоративных или публичных глобальных. Без системы управления в таких сетях нужно присутствие квалифицированных специалистов по эксплуатации в каждом здании каждого города, где установлено оборудование сети, что в итоге приводит к необходимости содержания огромного штата обслуживающего персонала.
В настоящее время в области систем управления сетями много нерешенных проблем. Явно недостаточно действительно удобных, компактных и многопротокольных средств управления сетью. Большинство существующих средств вовсе не управляют сетью, а всего лишь осуществляют наблюдение за ее работой. Они следят за сетью, но не выполняют активных действий, если с сетью что-то произошло или может произойти. Мало масштабируемых систем, способных обслуживать как сети масштаба отдела, так и сети масштаба предприятия, — очень многие системы управляют только отдельными элементами сети и не анализируют способность сети выполнять качественную передачу данных между конечными пользователями сети.
Совместимость или интегрируемость означает, что сеть способна включать в себя самое разнообразное программное и аппаратное обеспечение, то есть в ней могут сосуществовать различные операционные системы, поддерживающие разные стеки коммуникационных протоколов, и работать аппаратные средства и приложения от разных производителей. Сеть, состоящая из разнотипных элементов, называется неоднородной или гетерогенной, а если гетерогенная сеть работает без проблем, то она является интегрированной. Основной путь построения интегрированных сетей — использование модулей, выполненных в соответствии с открытыми стандартами и спецификациями.
Требования к распределенным системам
Эффективная распределенная система должна обладать следующими свойствами: прозрачность (англ, transparency), открытость (англ, openness), безопасность (англ, security), масштабирование (англ, scalability). Однако стоит отметить, что, несмотря на кажущуюся простоту и очевидность перечисленных свойств, их реализация на практике часто представляет собой непростую задачу.
Прозрачность (Transparency)
Под прозрачностью распределенной системы понимают ее способность скрывать свою распределенную природу, а именно, распределение процессов и ресурсов по множеству компьютеров, и представляться для пользователей и разработчиков приложений в виде единой централизованной компьютерной системы. Стандарты эталонной модели для распределенной обработки в открытых системах Reference Model for Open Distributed Processing (RM-ODP) определяют несколько типов прозрачности. Наиболее важные из них перечислены ниже.
- • Прозрачность доступа (англ, access transparency). Вне зависимости от способов доступа к ресурсам и их внутреннего представления, обращения к локальным и удаленным ресурсам осуществляется одинаковым образом. На базовом уровне скрывается разница архитектур вычислительных платформ, но, что более важно, достигается соглашение о том, как ресурсы разнородных машин, будут представляться пользователям распределенной системы единым образом. В качестве примера можно привести прикладной программный интерфейс (англ, application programming interface, API) для работы с файлами, хранящимися на множестве компьютеров различных архитектур, который предоставляет одинаковые вызовы операций как с локальными, так и с удаленными файлами.
- • Прозрачность местоположения (англ, location transparency). Позволяет обращаться к ресурсам без знания их физического местоположения. В этом случае имя запрашиваемого ресурса не должно давать никакого представления о том, где ресурс расположен. Поэтому важную роль для обеспечения прозрачности местоположения играет именование ресурсов. Например, чтобы отправить электронное сообщение на адрес Этот адрес e-mail защищен от спам-ботов. Чтобы увидеть его, у Вас должен быть включен Java-Script не требуется знать физического местоположения получателя, его почтового ящика или почтового сервера. В свою очередь обращение к файлу serverfoo подразумевает знание имени сервера, на котором он расположен, а значит, не является полностью прозрачным с точки зрения местоположения.
- • Прозрачность перемещения (англ. migration transparency). Перемещение ресурса или процесса в другое физическое местоположение остается незаметным для пользователя распределенной системы. Здесь стоит отметить, что выполнение требования прозрачности местоположения не гарантирует прозрачности перемещения. Другими словами, если распределенная система скрывает местоположение ресурса, это не означает, что его можно сменить незаметно для пользователя. Например, распределенные файловые системы позволяют монтировать файловые системы удаленных компьютеров в локальное пространство имен клиента, предоставляя единое дерево каталогов и тем самым обеспечивая прозрачность местоположения. Однако если файлы на удаленных компьютерах будут перемещены в другое место, в большей части распределенных файловых систем они станут недоступны для пользователя.
- • Прозрачность смены местоположения (англ. relocation transparency). Более строгое по отношению к предыдущему требование скрыть факт перемещения ресурса во время его использования. Примером могут служить мобильные пользователи, использующие сотовые телефоны. В этом случае, если рассматривать вызывающего абонента в качестве пользователя распределенной системы, а вызываемого — в качестве ее ресурса, то система будет прозрачной с точки зрения смены местоположения. Действительно, перемещение «ресурса» из соты в соту в процессе разговора остается незаметным для звонящего.
- • Прозрачность репликации (англ, replication transparency). Если для повышения доступности или увеличения производительности используется несколько копий ресурса (реплик), этот факт остается скрытым от пользователя, и он полагает, что в системе присутствует только один экземпляр ресурса. Для обеспечения прозрачности репликации необходимо, чтобы все реплики имели одно и то же имя, очевидно, не зависящее от местоположения копии ресурса. Таким образом, системы, которые обеспечивают прозрачность репликации, также должны поддерживать и прозрачность местоположения.
- • Прозрачность одновременного доступа (англ. concurrency transparency). Позволяет нескольким пользователям (конкурирующим процессам) одновременно выполнять операции над общим, совместно используемым ресурсом без взаимного влияния друг на друга. Иначе говоря, скрывается факт использования ресурса другими пользователями (процессами). Стоит отметить, что сам ресурс должен оставаться в непротиворечивом состоянии, что может достигаться, например, с помощью механизма блокировок, когда пользователи (процессы) по очереди получают исключительные права на запрашиваемый ресурс.
- • Прозрачность отказов (англ, failure transparency). Подразумевается, что система должна пытаться скрывать частичные отказы, позволяя пользователям и приложениям выполнить свою работу вне зависимости от сбоев в аппаратных или программных компонентах распределенной системы, а также скрывать факт их последующего восстановления. В связи с тем, что любой процесс, компьютер или сетевое соединение могут отказывать независимо от других в произвольные моменты времени, каждый компонент распределенной системы должен быть готов к сбоям в других компонентах и обрабатывать подобные ситуации соответствующим образом.
Степень прозрачности. Важно отметить, что степень, до которой каждое из перечисленных выше свойств должно быть выполнено, может сильно варьироваться в зависимости от задач построения распределенной системы. Действительно, полностью скрыть распределение процессов и ресурсов вряд ли удастся. Из-за ограничения в скорости передачи сигнала, задержка на обращение к ресурсам, территориально удаленным от клиента, всегда будет больше, чем к ресурсам, расположенным поблизости.
Поэтому не каждая система в состоянии или даже должна пытаться скрывать все свои особенности от пользователя. Обычно, это утверждение выражается в поиске компромисса между прозрачностью распределенной системы и ее производительностью.
Например, если для повышения отказоустойчивости в системе присутствуют географически распределенные копии ресурса, то поддержка их идентичного состояния для обеспечения прозрачности репликации потребует гораздо большего времени выполнения каждой операции обновления. Другими словами, каждая операция обновления должна будет распространиться на все реплики до того, как будет разрешена следующая операция с данным ресурсом. Или, например, многие приложения предпринимают несколько последовательных попыток связаться с сервером, пытаясь скрыть его временную недоступность, тем самым замедляя работу системы. Однако, в некоторых случаях, например, если на самом деле сервер вышел из строя, было бы разумнее сразу уведомить пользователя о недоступности ресурса.
§ 4. Прозрачность в распределенных системах.
Существует много измерений прозрачности. Они составляют важную часть Международного стандарта по открытой распределенной обработке [ ISO / IEC , 1996].
Прозрачность в распределенных системах имеет несколько различных измерений:
SHAPE * MERGEFORMAT 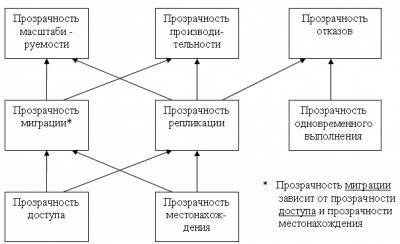
Рис. 1.5. Измерение прозрачности в распределенных системах .
§ 4.1. Прозрачность доступа.
Прозрачность доступа требует, чтобы интерфейс заявки на обслуживание был одним и тем же для связи между компонентами разных хостов [т.е. подразумевается одинаковость интерфейсов для локальной и удаленной связи]. Компонент, к которому нет прозрачного доступа, нельзя перенести с одного хоста на другой. Для этого необходимо изменить все остальные компоненты, запрашивающие услуги, чтобы они могли использовать другой интерфейс.
§ 4.2. Прозрачность местонахождения.
Прозрачность местонахождения означает, что запрашивающему обслуживание объекту не требуется знать о физическом расположении компонента (т.е. хоста).
§ 4.3. Прозрачность миграции.
Иногда возникает необходимость в переносе компонента с одного хоста на другой. Это может быть вызвано перегрузкой хоста или заменой аппаратурой. Такое перемещение компонентов называется миграцией.
§ 4.4. Прозрачность репликации.
Иногда бывает полезно держать копии компонента на разных хостах. Однако эти копии должны быть связаны друг с другом. Если у них меняется внутреннее состояние, то оно должно быть синхронизировано во всех опиях. Копии компонента, удовлетворяющие этому требованию, называются репликами. Процесс создания реплики и поддержания ее соответствия оригиналу называется репликацией.
Прозрачность репликации означает, что пользователям и программистам не требуется знать, кто представляет услуги – реплика или основной компонент.
§ 4.5. Прозрачность одновременного выполнения.
Прозрачность одновременного выполнения означает, что несколько компонентов могут одновременно запрашивать обслуживание у разделяемого компонента с сохранением его целостности, причем ни пользователи, ни разработчики не должны видеть, как реализована одновременная работа.
§ 4.6. Прозрачность масштабируемости.
Прозрачность масштабируемости – высокоуровневый критерий прозрачности, требующий, чтобы масштабирование системы с целью адаптации к растущей нагрузке было прозрачным, для разработчиков и пользователей. Прозрачность масштабирования похожа на прозрачность производительности в том, что в обоих случаях речь идет о качестве услуг, предоставляемых приложениями. Однако производительность рассматривается с точки зрения одиночной заявки, тогда как прозрачность масштабируемости определяет поведение системы при увеличении числа компонентов и параллельных заявок (Пример: сеть Интернет).
§ 4.7. Прозрачность производительности.
Прозрачность производительности означает, что пользователям и программистам не требуется знать, как поддерживается хорошая производительность системы. Рассматривая производительность, мы интересуемся эффективностью, с которой система может измеряться интервалом времени между двумя заявками или требуемой способностью.
§ 4.8. Прозрачность отказов.
Прозрачность отказов означает скрытие отказов от пользователей, клиентских и серверных компонентов. Следовательно, при проектировании компонентов можно не принимать во внимание возможность отказа тех служб, на которые они опираются. Прозрачность отказов подразумевает также, что разработчик сервера не должен принимать специальных компонентов после отказов.
Прозрачность системы
Прозрачность системы — Лекция, раздел Философия, Распределенные системы обработки информации Имеет Несколько Различных Аспектов: 1. Прозрачность Масштабируемости.
Имеет несколько различных аспектов:
1. Прозрачность масштабируемости (обеспечивается 4, 5)
2. Прозрачность производительности (обеспечивается 4, 5)
3. Прозрачность отказа (обеспечивается 5, 6)
4. Прозрачность миграции (обеспечивается 7, 8) – перемещение компонентов незаметно для пользователей и без специальных действий со стороны разработчиков этих компонентов
5. Прозрачность репликации (обеспечивается 7, 8) – пользователям и разработчика не требуется знать, кто предоставляет услугу – реплика или основной компонент. Разработчики компоненты не должны учитывать возможность его репликации
Реплика – копия, которая остается синхронизированной с оригиналом
6. Прозрачность одновременного выполнения
7. Прозрачность доступа – одинаковость интерфейсов для локальной и удаленной связи (интерфейс заявки на обслуживание должен быть одним и тем же для связи между компонентами одного хоста и разных хостов)
8. Прозрачность местонахождения – способ вызова операции не зависит от местонахождения компонента (запрашивающему обслуживание объекту не требуется знать о физическом расположении компонента)
Что бы достичь реализации, заявки на обслуживание должны подаваться одинаковым образом. Клиент не должен знать о местонахождении компонента или его реплики. Прозрачность одновременного выполнения означает, что пользователи программы не знают, что компоненты запрашивают услуги одновременно.
Несколько компонентов могут запрашивать обслуживание одновременно с сохранением его услов-ти. Пользователи и разработчики не видят, как организуется одновременно обслуживание.
Прозрачность масштабирования программист не должен знать, как достигается масштабируемость распределенной системы.
Прозрачность производительности – пользователь и программист не знают, как поддерживается хорошая производительность.
В основе балансировки нагрузки лежит реализация компонент.
Прозрачность отказа – пользователям и программистам не требуется знать, как ВС справляется с отказами.
Эта тема принадлежит разделу:
Распределенные системы обработки информации
Недашковский вячеслав михайлович.. язык java среда eclipse.. лекция литература кен а госменг дж холлез д язык программирования java е изд пер с англ м изд дом вильямс с..
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Прозрачность системы
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
Все темы данного раздела:
История и предпосылки
1991 Patric Norton – разработка языка, чтобы программировать бытовые устройства. · сделать машинонезависимый язык и не зависимый от процессоров. Для этого программы преобразуются в промежу
Обработка событий
Есть объекты событий – EventObject. Соответственно имеются типы событий: ActionEvent, WindowEvent и другие. Чтобы подписаться на событие: ОбъектИсточника.addСобытиеListner(объект слуш
Понятие распределенной системы
1. РС содержит компоненты, которые распределены по разным компьютерам., 2. Определение 2.1 Хост – компьютер, на котором размещены компоненты вычислительной системы: аппаратура и сетевая ОС
Требования к системе
· Функциональные — поддаются локализации при реализации · Нефункциональные — относятся к качеству системы – носят глобальный характер и оказывают существенное влияние на выбор общей архите
Удаленный вызов процедур
Есть машины: A и B. A вызывает процедуру, которая выполняется на B. count = read(fd, buf, bytes); Таблица 2.1. Стек при вызове процедуры bytes
Передача параметров по ссылке
Пример 11.Чтение удаленного файла. Передать копию ссылки не представляется возможным, так как ссылка – это указатель в адресном пространстве, бессмысленно передавать ее ко
Привязка клиента к объекту
Вот мы сказали, есть механизм удаленного вызова RPC и есть РО. Много общего. Различия: система с РО обычно предоставляет клиентам ссылки на объекты, причем они уникальны в пределах всей системы. Та
Идентификатор сервера
Разрешение имени представляет собой процесс доступа к именованной сущности. => для этого необходимо реализовать некоторую систему наименований. Имя – это последовательность битов, используемых д
О языке определения интерфейсов
Прежде чем обратится к методу объекта, клиент должен осуществить процесс связывания (в адресном пространстве клиента создается заместитель, представляющий образ удаленного объекта). С помощью замес
Адаптер объекта
1. Правила обращения к объекту называют политикой активизации. Прежде чем обратится к объекту, часто его надо поместить в адресное пространство сервера, то есть активизирован.
Перенос кода
Вообще-то передаются программы. Каковы же причины для переноса кода? Идет процесс. Принимается решение системы: взять исполняемый код и перенести его на другой компьютер. Задача дорогостоя
Трейдинг
позволяет клиентам определять местонахождения объекта в сервере исходя из предоставляемых объектами-серверами функций и требуемого качества обслуживания, то есть клиенты могут находить объекты-серв
Иерархические подходы в службах локализации
В такой иерархической схеме сеть делится на домены. Домен верхнего уровня охватывает всю сеть целиком. В свою очередь каждый домен делится на поддомены – иерархия. Домен самого нижнего уровня назыв
Объектный трейдинг
Бывают ситуации, когда клиент напрямую не может идентифицировать сервер. Тогда выход этого сервера по просьбе клиент осуществляет трейдер: он выбирает поставщика сервиса или сервера, опираясь на не
Логические часы. Алгоритм Лампорта
Есть ситуации, когда важно нет точное время выполнения процесса, а точная последовательность выполнения. Для таких случаев используют достаточно часто алгоритм Лампорта синхронизации логических час