Распознавание текста abbyy
Abbyy FineReader — Файн Ридер скачать бесплатно на русском
Abbyy FineReader – это широко известная программа для сканирования документов и распознавания текста. На сегодняшний день она является наиболее популярной благодаря понятному и удобному интерфейсу, большому набору всевозможных функций, связанный со сканированием и работой с готовым документом, а также удобством в использовании.

При помощи программы Файн Ридер можно:
Сканировать любой документ через ваш сканер и после распознать и сохранить для дальнейшего редактирования на компьютере, отправить по электронной почте, сохранить на флешке и т.д. Так же можно переводить изображения, сканы, PDF-файлы, фотографии в другие форматы, например, конвертировать их в таблицы и тексты без необходимости набирать текст заново. При этом распознаются многие форматы изображений, а форматирование текста часто остаётся не тронутым.
Файн Ридер программа для сканирования документов умеет работать со всеми сканерами включая самые популярные такие как Canon (Кэнон), HP, Kyocera (Куосера), Samsung (Самсунг) и другие.

Программа для сканирования может сохранить документ в редакторы — Word (Ворд), Excel (Эксель), OpenOffice, Adobe Acrobat а так же экспортировать файлы в облачные хранилища по вашему выбору.
| Название | Язык | Рейтинг: | Загрузки | |
 |
Abbyy FineReader 10 | На Русском | Хорошо 8/10 |
Скачать бесплатно >> |
|
Abbyy FineReader 11 | На Русском | Очень хорошо 9.7/10 |
Скачать бесплатно >> |
|
Abbyy FineReader 12 | На Русском | Очень хорошо 9.7/10 |
Скачать бесплатно >> |
|
Abbyy FineReader 14 | На Русском | Очень хорошо 9.8/10 |
Скачать бесплатно >> |
|
Abbyy FineReader 15 | На Русском | Очень хорошо 9.8/10 |
Скачать бесплатно >> |
Помимо широкого функционала эта программа для скана выпускается более, чем на 170 языках мира, в том числе и на русском. Скорость и эффективность работы, особенно в самой новой версии Abbyy FineReader, удивительны. А улучшенный редактор изображений позволяет сделать предварительную обработку сканов и фотографий.
Можно по своему желанию добавить или снизить яркость и контрастность, скорректировать погрешности, допущенные камерой. Это позволит как можно точнее распознать текст и области рисунков. Удобный и понятный даже впервые столкнувшемуся с программой человеку интерфейс, делает её незаменимым помощником как на рабочем месте, так и дома.
Как сканировать и распознать документ:
Если программа на русском все достаточно просто и понятно, версия скачанная с нашего сайта бесплатна.
На верхней панели достаточно большие значки основных функций, на скрине ниже 11 версия но и в других все примерно одинаково изменены лишь сами значки.
Для того чтоб распознать нужно сначала сканировать со сканера документ либо загрузить картинку например с текстом, после нажать на кнопочку Распознать.
После распознания и корректировки можно сохранять документ в редактируемый а также желаемый формат например ПДФ (PDF).
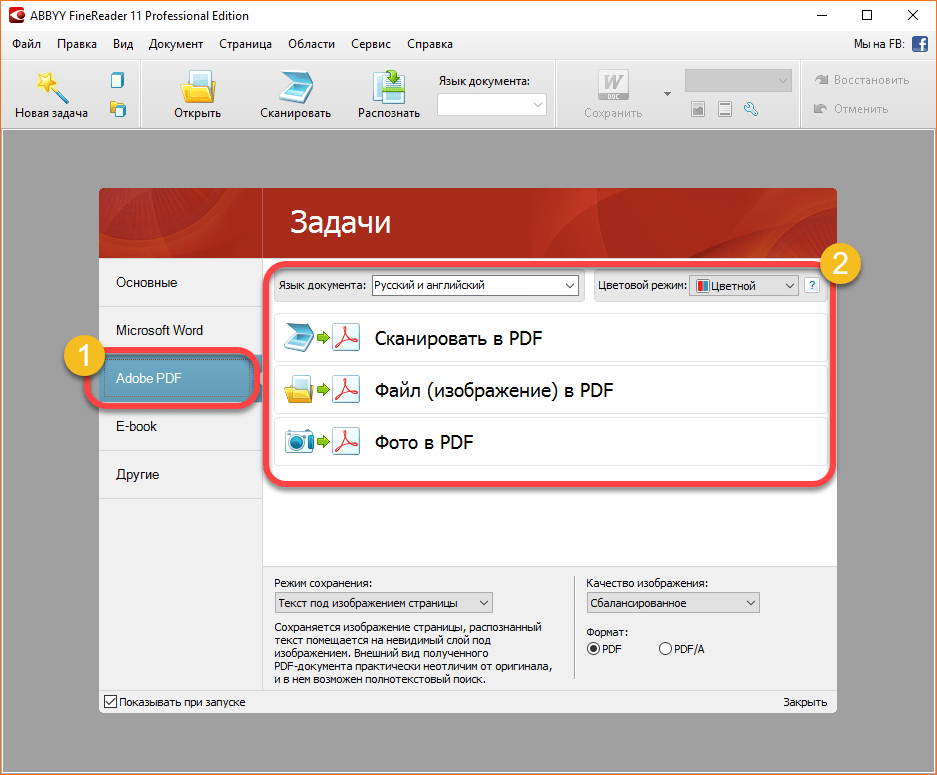
Настройки Файн Ридер программы:
При обычном использовании например только распознать или только сканировать углубленные настройки вообще не нужны.
Если все же вам необходимы доп. настройки то нажмите Сервис -> Опции. (для версии 11)
Из углубленных функций можно воспользоватся редактором языков если у вас текст который нужно распознать не Русский.
ABBYY FineReader 15 + ключ активации лицензионный 2021
Abbyy FineReader отлично подойдет для быстрой работы с сфотографированным текстом, оцифровки старых печатных изданий и даже перевода конспектов в электронный вид. Этот продукт российской компании ABBYY начиная с 2009 года удостаивался различных премий: «Лучший софт», «Лучшее профессиональное ПО» и проч.
Она позволяет быстро и качественно получить текст из отснятых или отсканированных документов, не меняя последовательности страниц в документе и их структуры. Полученный документ можно сохранять в разных форматах, просматривать, редактировать, искать по содержимому и прикреплять к электронным письмам. 
ABBYY FineReader: что это за программа
В основу FineReader Professional Edition положена технология OCR, заключающаяся в следующем: программа не подбирает загруженное в нее изображение символа, сравнивая с, возможно, бесчисленным множеством шаблонов в поисках подходящего, а делает несколько предположений, на что похож данный оптический объект, что это за знак, постепенно проверяя их.
Затем программа для сканирования выбирает наиболее похожий символ и ищет у исходного сходства с ним. Кроме того, программа способна самообучаться: оцифровывать части документа, опираясь на предыдущий опыт работы с этим же документом. К примеру, седьмая глава отсканированной книги будет обрабатываться несколько быстрее, чем первая, именно за счет обучаемости софта.
Необязательно загружать отсканированные файлы – достаточно будет фотографии с телефона или фотоаппарата(минимально допустимые характеристики – 2МП + автофокус), которую затем можно отредактировать во встроенном редакторе изображений. Кроме того, в ней можно сделать снимок части экрана – screenshot.
Продукт поддерживает более 190 языков, из которых в 48 встроена поддержка орфографии; используемые в файле языки можно настроить заранее или позволить определить самостоятельно. Также вручную можно задать тип обрабатываемого участка: рисунок, таблица, текст. При помощи технологии ADRT сохраняется не только исходная структура документа – нумерация страниц, оглавление, примечания – но даже расположение на странице текста и таблиц.
Для устройств под управлением windows 7 и windows 10 основные задачи(сценарии) доступны прямо из главного окна. А для системы windows 8 в дополнение к ним поддерживаются базовые жесты для сенсорных устройств, такие как масштабирование и прокрутка. В процессе работы можно выбрать, что важнее в данном конкретном случае: скорость или качество работы, и экономить до 50% времени.
С какими форматами работает?
В большинстве случаев Файн Ридер используется для работы с форматом PDF, однако он способен сохранять обработанные файлы не только в нем:
- RTF.
- DOC.
- DOCX.
- DJVU.
- ODT.
- PPT.
- TXT.
- DBF.
- CSV.
- LIT.
- Fb2.
- Epub.
- Создавать HTML-документы.
Кроме того, его можно запускать прямо из пакета Microsoft Office(Excel,Word,Outlook) и сохранять готовые документы в облако. На примере это можно рассмотреть так: документ, высланный вам по почте, находится в формате PDF. Вы откроете его в FineReaderе, распознаете и преобразуете в word-файл, отредактируете как вам необходимо, и сохраните в формате пакета OpenOffice Writer – ODT. Или снова в PDF или оставите в DOC.

Установка
Установщик предоставляется бесплатно и без регистрации. После скачивания файла вы увидите в папке загрузки текстовый документ README.txt и приложение ABBYY.FineReader.v12.0.101.496.exe.

Закройте все окна Microsoft Office. Запустите установчник 

Выберите адрес каталога, куда нужно будет установить программу, «обычный» режим установки

и необходимые опции перед началом установки: рекомендуется убрать галочки во всех строках, кроме второй: «Создать ярлык для ABBYY FineReader 12 на рабочем столе».

После этого ждите окончания процесса. Установка обычно занимает около 10 минут, но не завершайте процесс, не дождавшись окончания: на «засоренном» компьютере она может длиться до получаса или часа.

После появления окна, сообщающего о завершении установки, нажмите кнопку «готово», и программой можно пользоваться – ключик активации уже встроен в файлы.

Интерфейс
Последняя версия ABBYY FineReader 12 обладает дружелюбным пользователю интерфейсом. Верхняя строка разделена на вкладки:
- Файл
- Правка
- Вид
- Документ
- Страница
- Область
- Сервис
- Справка

Основная используемая вкладка «Файл» содержит в себе опции «Новая задача», «Сканировать страницы», «Открыть PDF или изображение», «Сохранить документ», «Отправить по электронной почте», «Печать» и т.д. 
По умолчанию при старте приложения открывается окно «Задача»

Которое также можно вызвать одноименной кнопкой в верхней левой части экрана. В подпунктах можно выбрать одну из стандартных задач – конвертирование, создание электронных таблиц и т.п.- или создать свою пользовательскую задачу.
Слева находится вертикальный список из нескольких пунктов – смотря с чем необходимо работать:
- «Основные» — отображает наиболее популярные действия, такие как быстрое сканирование, сканирование в PDF и Microsoft Word;
- «Microsoft Word», «Excel», Adobe PDF — здесь показываются действия-связки Файнридера и Ворда, Экселя, PDF соответственно, например, «Сканировать в..»;
- В пункте «Другие» находятся кнопки сканирование в прочие и редко используемые форматы: HTML,EPUB и т.д;
- В «Моих задачах» можно создать персонально-ориентированную задачу, облегчающую повседневную работу.
Выбор языка для работы с файлом
Во вкладке настройки можно изменить «Выбор языка», для распознавания текста файла. 

Цветовой режим
В меню «Цветовой режим» предлагается выбрать из цветного или черно-белого, причем во втором случае объем выдаваемого файла будет меньше и время на обработку уменьшится. 
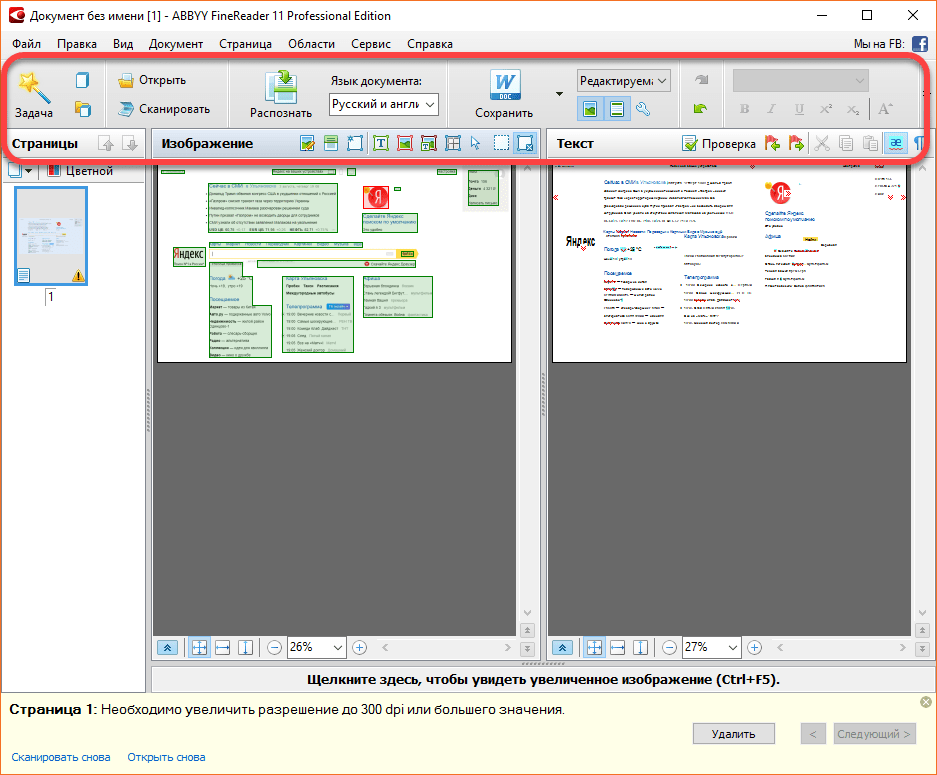
На панели окна Изображение можно выбрать и отметить области распознавания, проверить результат работы и двух сопоставляемых (слева и справа) окнах. В правом – результате распознавания – при помощи встроенного текстового редактора правки можно вносить прямо в нем.
Программа выделяет 4 вида областей:
- Текст
- Картинка
- Фоновая картинка
- Таблица
После выполнения всех манипуляций необходимо запустить распознавание текста снова. Стоит заметить, что распознавать можно только отдельную область без обработки всех остальных страниц документа, что упрощает работу с большими файлами – просто выделите ее и нажмите кнопку «копировать». Необходимо знать, что рукописные тексты программа распознать не сможет. На примере ниже представлен неправильно выбранный документ, не подлежащий обработке.

Как пользоваться
Ознакомьтесь визуально с принципом работы данной программы:
Горячие клавиши
Помимо основных, отображаемых в пользовательском интерфейсе, клавиш, в FineReader существуют т.н. «горячие клавиши». Ниже приведен их неполный список.
Стандартные команды, знакомые нам по пакету MS Office:
- Ctrl+S – сохранение документа
- Ctrl+P – напечатать документ/текст
- Ctrl+Z – отмена предыдущей команды
- Ctrl+X, Ctrl+C, Ctrl+V – вырезать, скопировать, вставить текст/изображение
- И др.
Распознавание текста в ABBYY FineReader (1/2)
Систему распознавания текста в FineReader можно описать очень просто.
У нас есть страница с текстом, мы разбираем ее на текстовые блоки, затем блоки разбираем на отдельные строчки, строчки на слова, слова на буквы, буквы распознаем, дальше по цепочке собираем все обратно в текст страницы.

Выглядит очень просто, но дьявол, как обычно, кроется в деталях.
Про уровень от документа до строки текста поговорим как-нибудь в следующий раз. Это большая система, в которой есть много своих сложностей. В качестве некоторого введения, пожалуй, можно оставить здесь вот такую иллюстрацию к алгоритму выделения строк.

В этой статье мы начнём рассказ про распознавание текста от уровня строки и ниже.
Небольшое предупреждение: система распознавания FineReader – очень большая и постоянно дорабатывается в течение многих лет. Описывать эту систему целиком со всеми ее нюансами, во-первых, лучше кодом, во-вторых, займет очень-очень много места, в-третьих, почитайте это. Поэтому к написанному далее рекомендуем относиться как к некой очень обобщенной теории, стоящей за практической системой. То есть общие идеи и направления в технологии примерно похожи на правду, но чтобы понять до мелочей, что же там на практике происходит, лучше не читать эту статью, а работать у нас над разработкой этой системы.
Граф линейного деления
Итак, у нас есть черно-белое изображение строки текста. На самом деле изображение, конечно, серое или цветное, а черно-белым становится после бинаризации (про бинаризацию тоже нужно писать отдельную статью, а пока отчасти может помочь вот это).
Так вот, пусть есть черно-белое изображение строки текста. Нужно его поделить на слова, а слова — на символы для распознавания. Базовая идея, как обычно, очевидна – ищем на изображении строки вертикальные белые просветы, а дальше кластеризуем их по ширине: широкие просветы – это пробелы между словами, узкие – между символами.

Идея замечательная, но в реальной жизни ширина пробелов может быть очень неоднозначным показателем, к примеру, для текста с наклоном или неудачного сочетания символов или слипшегося текста.

Решений у проблемы, в общем, два. Решение первое – считать некую «видимую» ширину просветов. Человек может практически любой текст, даже на незнакомом языке, точно поделить на слова, а слова — на символы. Это происходит потому, что мозг фиксирует не вертикальное расстояние между символами, а некий видимый объем пустого пространства между ними. Решение хорошее, мы его, конечно, используем, только работает оно не всегда. К примеру, текст может быть повреждён при сканировании и некоторые нужные просветы могут уменьшиться или, наоборот, сильно увеличиться.
Это приводит нас ко второму решению – графу линейного деления. Идея в следующем – если есть несколько вариантов, где поделить строку на слова, а слова на буквы, то давайте отметим все возможные точки деления, которые мы смогли придумать. Кусок изображения между двумя отмеченными точками будем считать кандидатом буквы (или слова). Вариант графа линейного может быть простым, если текст хороший и нет проблем с определением точек деления или сложным, если изображение было плохое.


Теперь задача. Есть множества вершин графа, нужно найти путь от первой вершины до последней, проходящий через какое-то количество промежуточных вершин (не обязательно все) с наилучшим качеством. Начинаем думать, что это напоминает. Вспоминаем курс оптимального управления из института, понимаем, что это подозрительно похоже на задачи динамического программирования.
Давайте подумаем, что нам нужно, чтобы алгоритм перебора всех вариантов не взорвался.
Для каждой дуги в графе нужно определить её качество. Если мы работаем с графом линейного деления слова на символы, то каждая дуга у нас – это символ. В роли качества дуги мы используем уверенность распознавания символа (как её посчитать — поговорим позднее). А если работаем с ГЛД на уровне строки, то каждая дуга этого ГЛД – вариант распознавания слова, который в свою очередь был получен из символьного графа. То есть нам нужно уметь оценивать общее качество полного пути в графе линейного деления.
Качество полного пути в графе мы будем определять как сумму качества всех дуг МИНУС штраф за весь вариант. Почему именно минус? Это дает нам возможность быстро оценить максимально возможное качество варианта пути по сумме качества дуг этого пути, а это значит, что большинство вариантов мы будем отсекать еще до подсчета общего качества варианта.
Таким образом, для ГЛД мы приходим к стандартному алгоритму динамического программирования – находим точки линейного деления, строим путь от начала до конца по дугам с наибольшим качеством, высчитываем итоговую стоимость построенного варианта. А дальше перебираем пути в ГЛД в порядке уменьшения суммарного качества элементов с постоянным обновлением найденного лучшего варианта, пока не поймем, что все необработанные варианты заведомо хуже, чем текущий лучший вариант.
Гипотезы изображения
Прежде чем мы спустимся на уровень распознавания отдельных слов, у нас есть еще одна тема, которая не обсуждалась, – гипотезы изображения фрагмента.
Идея в следующем – у нас есть изображение текста, с которым мы собираемся работать. Очень хочется все изображения обрабатывать одинаковым образом, но правда в том, что в реальном мире изображения все разные – они могут быть получены из разных источников, они могут быть разного качества, они могут быть по-разному отсканированы.
С одной стороны, кажется, что разнообразие возможных искажений должно быть очень велико, но если начать разбираться, обнаруживается только ограниченный набор возможных искажений. Поэтому мы используем систему гипотез текста.
У нас есть предопределенный набор возможных гипотез проблемного текста. Для каждой гипотезы нужно определить:
- Быстрый способ выяснить, применима ли данная гипотеза к текущему изображению, причем сделать это только на основе характеристик изображения, до распознавания.
- Метод для исправления на изображении проблем конкретной гипотезы.
- Критерий качества правильности выбора гипотезы по итогам распознавания изображения, плюс, возможно, рекомендации для следующих гипотез.


На изображении выше можно увидеть гипотезы для различной бинаризации и контрастности исходного изображения.
В результате обработка гипотез выглядит так:
- По изображению сгенерировать наиболее подходящую гипотезу.
- Исправить искажения от выбранной гипотезы.
- Распознать полученное изображение.
- Оценить качество распознавания.
- Если качество распознавания улучшилось, то оценить, нужно ли применять новые гипотезы к измененному изображению.
- Если качество ухудшилось, то вернуться к исходному изображению и попробовать применить к нему какую-либо другую гипотезу.
На изображениях показано последовательное применение гипотез белого шума и сжатого текста.
Оценка качества слова
Остались нераскрытыми две важных темы: оценка общего качества распознавания слова и распознавание символов. Распознавание символа – тема на несколько разделов, поэтому сначала обсудим оценку качества распознанного слова.
Итак, у нас есть некий вариант распознавания слова. Первое, что приходит на ум, – проверить его по словарю и дать ему штраф, если оно в словаре не нашлось. Идея хорошая, но не все языки есть словари, не все слова в тексте могут быть словарными (имена собственные, к примеру), и, если уж мы углубляемся в сложности, – не всё в тексте вообще может быть словами в стандартном понимании этого термина.
Чуть раньше мы говорили, что любые оценки за слово целиком должны быть отрицательными, чтобы у нас нормально работал перебор по ГЛД. Сейчас нам это начнет активно мешать, поэтому давайте зафиксируем, что у нас есть некая заранее определенная максимальная положительная оценка слова, слову мы даем положительные бонусы, а финальный отрицательный штраф определяем как разность набранных бонусов и максимальной оценки.
Ок, пусть мы распознаём фразу «Вася прилетает рейсом SU106 в 23.55 20/07/2015». Мы, конечно, можем оценивать здесь качество каждого слова по общим правилам, но это будет достаточно странно. Скажем, и SU106 и Вася вполне понятные в данной строке слова, но очевидно, что правила образования у них разные и, по идее, верификация тоже должна быть разной
Отсюда появляется идея моделей. Модель слова – это некое обобщенное описание конкретного типа слов в языке. У нас, конечно, будет модель стандартного слова в языке, но также будут модели чисел, аббревиатур, дат, сокращений, имен собственных, URL и т.д.
Что нам дают модели и как их нормально использовать? Фактически мы обращаем в обратную сторону нашу систему проверки слова – вместо того чтобы для варианта слова долго узнавать, что же это такое, мы даем каждой модели решать, подходит ли ей данный вариант слова и насколько хорошо она его оценивает.

Из самой постановки задачи формируются наши требования к архитектуре модели. Модель должна уметь:
- Быстро сказать, подходит или нет для нее вариант слова. Стандартная проверка включает все проверки разрешенных наборов символов для каждой буквы в слове. Скажем, в словарном слове пунктуация должна быть только в начале или в конце, а в середине слова набор пунктуации сильно ограничен, и сочетание пунктуации сильно ограничено (супер-способность?!), а в модели числа в основном должны быть цифры, кроме разрешенного в данном языке символьного суффикса (10-ое, 10 th ).
- Уметь по своей внутренней логике оценить качество распознаваемого слова. К примеру, слово из словаря должно явно оцениваться выше, чем просто набор символов.
При оценке качества модели не стоит забывать, что наша задача в итоге – сравнивать модели между собой, поэтому их оценки должны быть согласованы. Более-менее нормальный способ этого добиться – это относиться к оценке модели как к оценке вероятности построить слово по данной модели. Скажем, словарных слов в обычном языке достаточно много, и получить словарное слово при неправильном распознавании несложно. А вот собрать нормальный, подходящий под все правила телефонный номер уже гораздо сложнее.
В итоге при распознавании некоторого фрагмента строки у нас получается примерно такая схема:
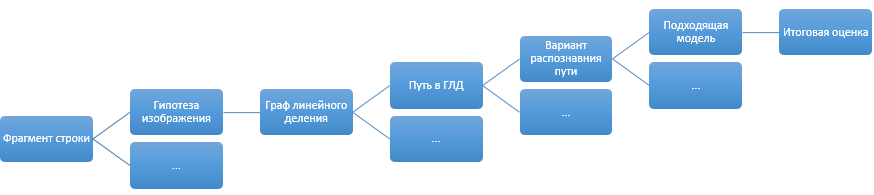
Отдельным пунктом при оценке вариантов распознавания идут дополнительные эмпирические штрафы, не вписывающиеся ни в концепцию моделей, ни в оценку распознавания. Скажем, «ООО Рога и копыта» и «000 Рога и копыта» выглядят как два одинаково нормальных варианта (особенно если в шрифте 0 (ноль) и О (буква О) слабо отличаются пропорциями). Но при этом достаточно очевидно, какой вариант распознавания должен быть правильным. Для таких небольших конкретных знаний о мире сделана отдельная система правил, которая может дополнительно штрафовать не понравившиеся ей варианты после оценок моделей.
Про само распознавание поговорим уже в следующей части этого поста. Подписывайтесь на блог компании, чтобы не пропустить 🙂
Как распознать текст с помощью ABBYY FineReader: пошаговая инструкция

В этот раз расскажу как превращать бумажные документы в электронный вид формата PDF, а также, как бумажный документ перекинуть в компьютер с целью изменить текст. Итак начнем.
У меня на руках бумажный документ.
СКАНИРОВАНИЕ в PDF
Задача: перекинуть в компьютер (перевести в электронный вид) этот документ. Притом нужно сделать именно в таком виде чтобы нельзя было его в будущем изменить (грубо говоря надо сделать фото документа). Потом этот электронный документ нужно переслать по почте на электронный адрес. Притом клиент просит именно в формате pdf.
По этапам:
1) пропускаю документ через сканер
2) сохраняю полученный отпечаток в формате pdf на свой компьютер
3) пересылаю полученный файл по почте
В своей работе я использую для решения такой задачи 2 программы:
Foxit Phantom или ABBYY FineReader. Для понятности прикладываю скриншоты:
В Foxit Phantom при включенном сканере необходимо в главном меню выбрать ФАЙЛ-СОЗДАТЬ PDF-СО СКАНЕРА…
Произойдет сканирование и появится предложение сохранить файл. Выбираем место, пишем название файла и сохраняем.

В ABBYY FineReader в панели инструментов есть огромные кнопки. Одна из них называется СКАНИРОВАТЬ в PDF. Её и используем.

Если же надо отсканировать многостраничный документ то, по этапам:
1) Нажимаем кнопку под номером 1 СКАНИРОВАНИЕ

Получаем отсканированный документ

Также сканируем ещё одну страницу (нажимаем ещё раз кнопку под номером 1 СКАНИРОВАНИЕ).
2) Сохраняем в PDF


В итоге получаем готовый многостраничный документ в виде файла в формате PDF.

Теперь данный файл можно отправлять по электронной почте.
РАСПОЗНАВАНИЕ ТЕКСТА
Задача: перевести бумажный документ в электронный вид (в компьютер)
По этапам:
1) Сканирование (кнопка 1 СКАНИРОВАНИЕ)

2) Распознавание (кнопка 2 РАСПОЗНАТЬ ВСЕ)

Распознавание нужно понимать как процесс перевода фотографии (картинки) в текст (буквы, цифры, знаки). Если Вы сфотографировали текстовую страницу, то после распознавания 99% текста с бумаги превратиться в текст электронный. Электронный текст уже можно на компьютере менять (редактировать) так, как Вам захочется.
3) Сохранение в текстовый редактор (кнопка 4 Сохранить)
Советую выбирать ПЕРЕДАТЬ ВСЕ СТРАНИЦЫ В—MICROSOFT WORD


Хотелось бы указать на важные моменты при процедуре РАСПОЗНАВАНИЯ. Есть нюансы при работе.
Сразу после распознавания советую поглядеть на результат. Особенно на блоки, которые создает программа FineReader.

Это области выделенные в прямоугольные рамки. Рамки эти разного цвета. Если красного цвета-то этот блок распознался как КАРТИНКА. Если черного цвета — то ТЕКСТ. Блоки бывают разного типа. Тип блока можно узнать щелкнув на блоке ПРАВОЙ клавишей мыши и выбрав ИЗМЕНИТЬ ТИП БЛОКА.

Маленькая хитрость: можно выделить произвольную область и пометить любым типом блок. Например выделим ту часть текста, которая плохо распознается, при помощи левой клавиши мыши (нажимает, удерживаем и тянем, рамка меняет размер).



В итоге документ в Word-е будет иметь блок текста и блок картинка. Блок картинка будет иметь абсолютно неизменный вид. Данный способ я использую при сохранении печатей, нестандартных шрифтов, картинок, фотографий.
ЗЫ: Знания и умения работать с PDF, сканировать и распознавать документы очень часто выручают в офисной работе. Знание — экономит Ваше время!
ABBYY
Softline — ABBYY Premium Reseller
Скачать прайс-лист Adobe Systems

ABBYY Finereader PDF 15 Business

ABBYY Finereader PDF 15 Standard

ABBYY FineReader Pro for Mac
Цена: 10 788 руб.

ABBYY Comparator
Цена: 33 990 руб.

ABBYY Lingvo x6 English

ABBYY Finereader PDF 15 Corporate
Цена: 18 990 руб.

ABBYY Lingvo x6 European

ABBYY Screenshot Reader

ABBYY Timeline
Цена: 936 000 руб.

ABBYY Lingvo x6 Multilingual

ABBYY Aligner
Цена: 49 920 руб.

ABBYY FlexiCapture
- предыдущая
- 1
- 2
- следующая
- 12
- 24
- 36
- 48
- 60
Информация о производителе
Российская компания ABBYY, которая до 1997 года имела название BIT Software, была основана в 1989 году. Сегодня ABBYY занимает лидирующие мировые позиции по производству лингвистического программного обеспечения, а именно программ для обработки естественного языка и распознавания всевозможных документов. Компания производит различного рода технологии искусственного интеллекта, программы для интеграции данных в ПК и обеспечивает качественный перевод этой информации с одного языка на другой.
На сегодняшний день ABBYY активно работает на международном рынке. Программы компании доступны для пользователей более чем в 100 странах мира. Технологии искусственного интеллекта ABBYY активно используются в продукции мировых производителей аппаратного, программного обеспечения и электроники. Благодаря тому, что программное обеспечение компании имеет высокое качество и простоту использования, оно признано лучшим в своей сфере.
Популярные продукты:
- ABBYY FineReader – программа предназначена для распознавания текстовых документов.
- ABBYY PDF Transformer – программа для работы с PDF файлами.
- ABBYY Lingvo – электронные словари для мобильных устройств и настольных компьютеров.
- ABBYY FlexiCapture 10 Professional – программа для потоковой интеграции данных и документов.
- ABBYY FineReader «Банк» – программа для ввода данных с платежных поручений и иных банковских документов.
Купить продукцию ABBYY вы можете в нашем интернет-магазине.
Общие правила лицензирования
Лицензирование продуктов ABBYY для индивидуального заказчика предполагает использование программы только на одном рабочем месте. Помимо полнофункциональной лицензии (Standalone), существует испытательная версия программы, ограниченная либо по сроку действия, либо по функционалу. Лицензия Standalone поставляется в коробках или в составе электронных версий продуктов. Данная лицензия позволяет установить ПО только на одно рабочее место, при этом использование программы в сети невозможно.
Лицензирование продуктов ABBYY для корпоративных заказчиков предусмотрено по трем схемам: Per Seat, Concurrent и Remote User. Кроме того, возможна покупка именных лицензий или неименных пакетов. Именной сертификат отличается от неименного тем, что в нем указывается название организации и ее адрес.
Программа лицензирования Per Seat
Per Seat – схема, по которой одна лицензия данного типа устанавливается и используется только на одном рабочем месте. Возможны два типа установки ПО ABBYY: серверная и локальная. Серверная установка состоит из двух этапов: установка программы на сервер и «развертывание» ее на рабочие станции. Серверная инсталляция удобна при наличии в офисе большого количества ПК, объединенных в локальную сеть.
Локальная установка на рабочие станции выполняется, как и серверная, с одного дистрибутива. При этом IT-специалист должен последовательно повторять процедуру установки программы, переходя с дистрибутивом от одного рабочего места к другому и набирая на каждом месте серийные номера, которые указаны в лицензионном сертификате. Данный способ лицензирования удобен при отсутствии локальной сети или в тех случаях, когда требуемое количество установок невелико. Лицензии Per Seat рекомендуются для компьютеров, которые могут быть отключены от корпоративной сети, например, для ноутбуков.
Программа лицензирования Concurrent
Concurrent – схема, по которой ПО ABBYY может быть установлено на неограниченном количестве компьютеров, но одновременно им можно пользоваться на количестве рабочих станций, не превышающем объем закупленных лицензий. При выборе лицензии Concurrent возможна только сетевая установка программы (приобретение таких лицензий для установки на компьютеры вне локальной сети не имеет смысла).
Программа лицензирования Remote User
Лицензии типа Remote User для ABBYY FineReader PDF 15 можно установить и использовать только на терминальном сервере, при этом общее количество отдельных пользователей, получающих доступ к программе через терминальные службы, не должно превышать количество приобретённых лицензий (принцип доступа «на рабочее место»). Для использования в конкурентном режиме на терминальном сервере также возможно использование лицензий ABBYY FineReader типа Concurrent
Лицензирование академических и медицинских организаций
Для учебных и медицинских заведений при покупке продуктов FineReader, Lingvo, PDF Transformer предусмотрена скидка. Организации, имеющие право на приобретение ПО ABBYY по льготной цене:
- Государственные высшие, средние и средне-специальные образовательные учебные заведения.
- Государственные дошкольные учреждения.
- Государственные больницы и клиники, подведомственные Министерству здравоохранения.
- Учебные центры, имеющие лицензии на ведение образовательной деятельности, выданные Министерством общего и профессионального образования или другим уполномоченным государственным органом.
- Государственные библиотеки.
Скидка предоставляется только при наличии официального письма от учебного/медицинского заведения.
Особенности ценовой политики
Для определения уровня скидки в одном заказе суммируются все лицензии в рамках одной продуктовой линейки. Количество лицензий, заказанных в разное время, не суммируется для увеличения уровня скидки, учитывается только размер самого крупного заказа. Уровень скидки закрепляется за клиентом и действует в рамках одной версии продукта. В течение этого срока заказчик может покупать дополнительные лицензии с учетом установленного уровня скидки в любом количестве.
При выходе новых версий продуктов старые версии снимаются с производства и продаж. Дозакупка лицензий предыдущих версий осуществляется по ценам аналогичных позиций актуальных версий. Несколько филиалов одной организации могут объединить свои заказы для достижения более высокого уровня скидки. Коробки и неименные пакеты лицензий не суммируются с именными пакетами лицензий.
✅ Купить продукцию производителя ABBYY на официальном сайте
✅ Лицензионный софт и оборудование по цене от 1490 руб.