Кириллица windows 1251
Кириллица windows 1251
Кодировка Windows-1251 является стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990-1991 годах совместно представителями «Параграфа», «Диалога» и российского отделения Microsoft. Первоначальный вариант кодировки сильно отличался от представленного ниже в таблице (в частности, там было значительное число «белых пятен»).
Возможно, просмотр некоторых символов у Вас будут отображаться не правильно. Зависит это от используемого шрифта, лучше установить шрифт Arial Unicode MS.
В 1990-91 годах, перед Microsoft серьёзно встала проблема локализации своих продуктов для советского рынка. Встал вопрос о кодировке, Microsoft запросил мнение российских программистов о кодовой таблице. И вот, в один прекрасный день человек 15-20 собралось в старом здании «Параграфа» на Петровском бульваре, чтобы выработать согласованное предложение для Microsoft. Председательствовал тогда Антон Чижов из «Параграфа», участвовали: Петр Квитек из «Диалога», Евгений Нестеренко, Игорь Баздырев (автор «ParaWin»), Андрей Чернов и другие.
Консенсус был достигнут довольно быстро, что доводы были примерно такие:
- алфавит должен быть упорядочен (кроме буквы ё);
- сначала uppercase, потом lowercase;
- колонки 80 и 90 — табу;
- колонка A0 отпала из-за того, что A0 — non-breakable space — использовался во всех word processors;
- буква «A» должна была быть в строке 0;
- не должно было быть разрывов.
В результате, осталось всего 2 варианта — четыре колонки B0-EF (кстати, ISO8859-5) и C0-FF. Решающим доводом в пользу второго варианта было то, что в Latin-1 (ISO8859-1) буквы с умлаутами были расположены в этих колонках.
Потом располагали ё и Ё, украинские и другие символы.
Конечно, вполне возможно, что выработанные рекомендации до Microsoft не дошли, или были им проигнорированы, но факт — русские буквы в cp1251 расположены именно так.
Windows-1251 выгодно отличается от других кириллических кодировок наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только значок ударения); она также содержит все символы для украинского, белорусского, сербского и болгарского языков. Хотя имеет два недостатка: (маленький) буква «я» (строчная) имеет код 0xFF (255 в 10-чной системе). Она является «виновницей» ряда неожиданных проблем в программах без поддержки чистого 8-го бита. И второе — отсутствуют символы псевдографики.
Нижняя часть таблицы кодировки (латиница) полностью соответствует кодировке ASCII. Числа под буквами обозначают 16-ричный код буквы в Юникоде.
В Юникоде первые 128 символов тоже совпадают с соответствующими символами ASCII.
(Показаны только отличающиеся строки, поскольку всё остальное совпадает с CP1251)
Кодировка CP1251-k (KazWin, казахская кодировка)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
| 8. | Ұ 4B0 |
Ғ 492 |
, 201A |
ғ 493 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Ө 4E8 |
‹ 2039 |
Ң 4A2 |
Қ 49A |
Һ 4BA |
Ү 4AE |
| 9. | ұ 4B1 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
ө 4E9 |
› 203A |
ң 4A3 |
қ 49B |
һ 4BB |
ү 4AF |
|
| A. | A0 | Ў 40E |
ў 45E |
Җ 496 |
¤ A4 |
Ҳ 4B2 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
— AD |
® AE |
Ї 407 |
| B. | ° B0 |
± B1 |
І 406 |
і 456 |
ҳ 4B3 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
җ 497 |
Ә 4D8 |
ә 4D9 |
ї 457 |
Кодировка Windows-1251 (чувашский вариант)
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
| 8. | Ђ 402 |
Ѓ 403 |
, 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Ӑ 4D0 |
Ӗ 4D6 |
Ҫ 4AA |
Ӳ 4F2 |
| 9. | ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
ӑ 4D1 |
Ӗ 4D7 |
ҫ 4AB |
ӳ 4F3 |
Кодировка Windows-1251 (татарский вариант)
Эта кодировка была официально принята в Татарстане в 1996 г.
Как исправить отображение кириллицы или кракозябры в Windows 10
Одна из возможных проблем, с которыми можно столкнуться после установки Windows 10 — кракозябры вместо русских букв в интерфейсе программ, а также в документах. Чаще неправильное отображение кириллицы встречается в изначально англоязычных и не совсем лицензионных версиях системы, но бывают и исключения.
В этой инструкции — о том, как исправить «кракозябры» (или иероглифы), а точнее — отображение кириллицы в Windows 10 несколькими способами. Возможно, также будет полезным: Как установить и включить русский язык интерфейса в Windows 10 (для систем на английском и других языках).
Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
Самый простой и чаще всего работающий способ убрать кракозябры и вернуть русские буквы в Windows 10 — исправить некоторые неправильные настройки в параметрах системы.
Для этого потребуется выполнить следующие шаги (примечание: привожу также названия нужных пунктов на английском, так как иногда необходимость исправить кириллицу возникает в англоязычных версиях системы без нужды менять язык интерфейса).
- Откройте панель управления (для этого можно начать набирать «Панель управления» или «Control Panel» в поиске на панели задач.
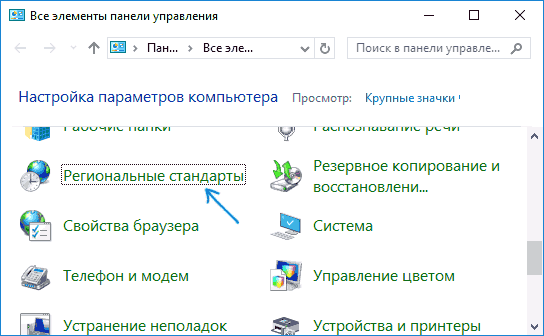
- Убедитесь, что в поле «Просмотр» (View by) установлено «Значки» (Icons) и выберите пункт «Региональные стандарты» (Region).

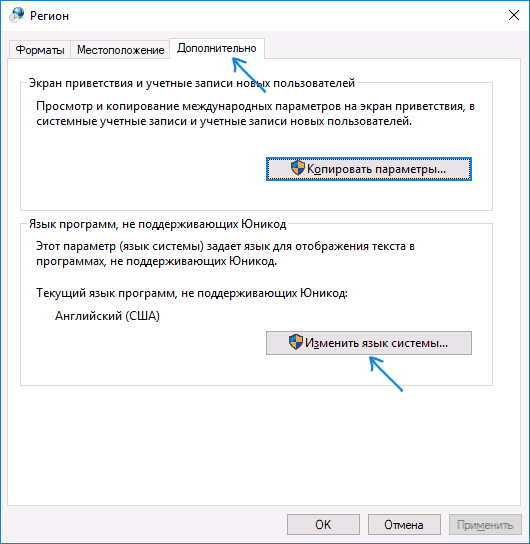
- На вкладке «Дополнительно» (Administrative) в разделе «Язык программ, не поддерживающих Юникод» (Language for non-Unicode programs) нажмите по кнопке «Изменить язык системы» (Change system locale).
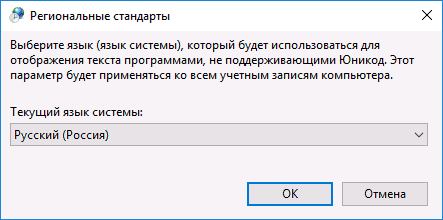
- Выберите русский язык, нажмите «Ок» и подтвердите перезагрузку компьютера.
После перезагрузки проверьте, была ли решена проблема с отображением русских букв в интерфейсе программ и (или) документах — обычно, кракозябры бывают исправлены после этих простых действий.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
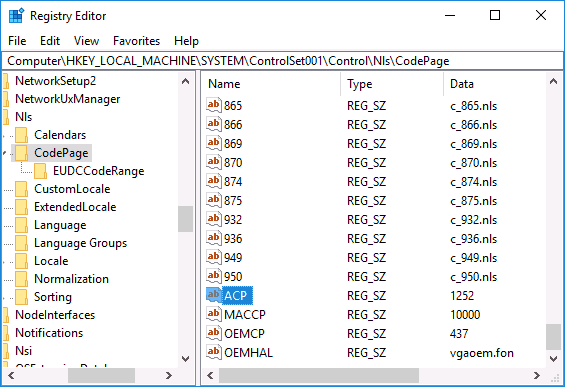
- Нажмите клавиши Win+R на клавиатуре, введите regedit и нажмите Enter, откроется редактор реестра.
- Перейдите к разделу реестраи в правой части пролистайте значения этого раздела до конца.
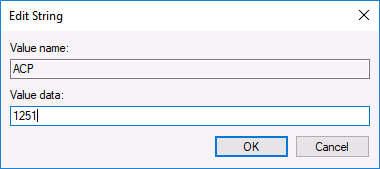
- Дважды нажмите по параметру ACP, установите значение 1251 (кодовая страница для кириллицы), нажмите Ок и закройте редактор реестра.
- Перезагрузите компьютер (именно перезагрузка, а не завершение работы и включение, в Windows 10 это может иметь значение).
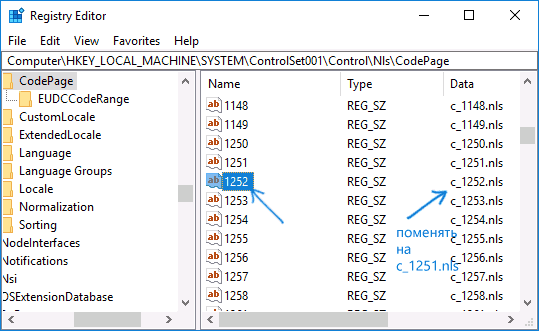
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C: Windows System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
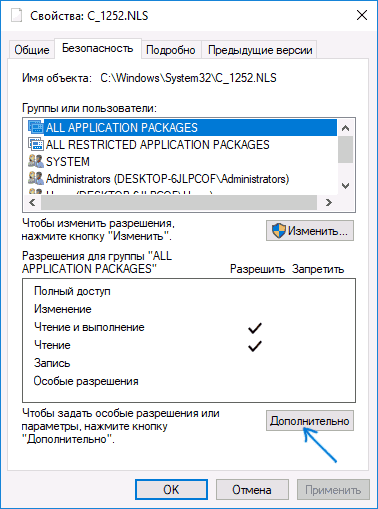
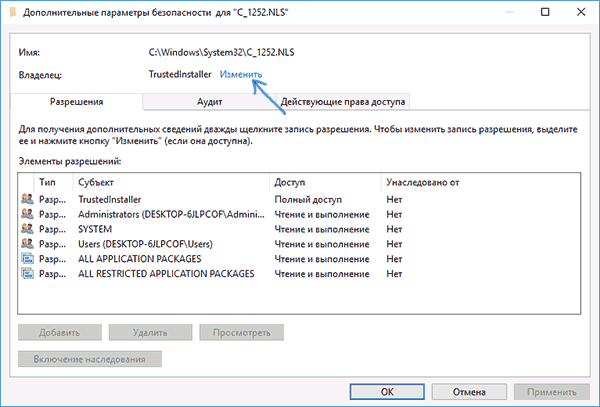
- Зайдите в папку C: Windows System32 и найдите файл c_1252.NLS, нажмите по нему правой кнопкой мыши, выберите пункт «Свойства» и откройте вкладку «Безопасность». На ней нажмите кнопку «Дополнительно».
- В поле «Владелец» нажмите «Изменить».
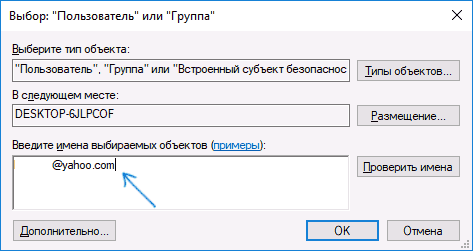
- В поле «Введите имена выбираемых объектов» укажите ваше имя пользователя (с правами администратора). Если в Windows 10 используется учетная запись Майкрософт, вместо имени пользователя укажите адрес электронной почты. Нажмите «Ок» в окне, где указывали пользователя и в следующем (Дополнительные параметры безопасности) окне.
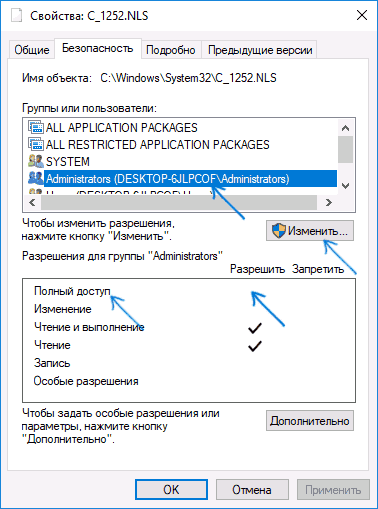
- Вы снова окажетесь на вкладке «Безопасность» в свойствах файла. Нажмите кнопку «Изменить».
- Выберите пункт «Администраторы» (Administrators) и включите полный доступ для них. Нажмите «Ок» и подтвердите изменение разрешений. Нажмите «Ок» в окне свойств файла.
- Переименуйте файл c_1252.NLS (например, измените расширение на .bak, чтобы не потерять этот файл).
- Удерживая клавишу Ctrl, перетащите находящийся там же в C:WindowsSystem32 файл c_1251.NLS (кодовая страница для кириллицы) в другое место этого же окна проводника, чтобы создать копию файла.
- Переименуйте копию файла c_1251.NLS в c_1252.NLS.
- Перезагрузите компьютер.
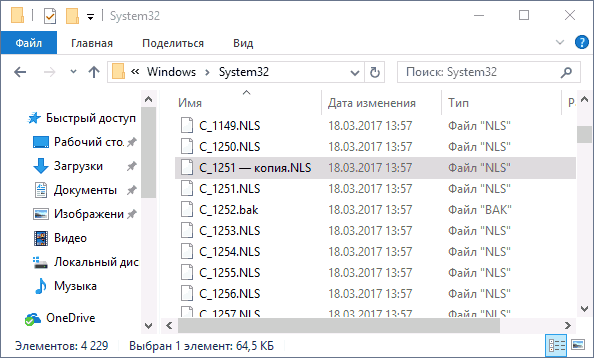
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
Выбор кодировки текста при открытии и сохранении файлов
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Нажмите кнопку Параметры.
Нажмите кнопку Дополнительно.
Перейдите к разделу Общие и установите флажок Подтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Нажмите кнопку Пуск и выберите пункт Панель управления.
Выполните одно из указанных ниже действий.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл.
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Нажмите кнопку Сохранить.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7)
Стандартный шрифт для стиля «Обычный» локализованной версии Word
Windows 1256, ASMO 708
Китайская (упрощенное письмо)
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ
Китайская (традиционное письмо)
BIG5, EUC-TW, ISO-2022-TW
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866
Английская, западноевропейская и другие, основанные на латинице
Кодировки UTF-8 и Windows 1251 — просто о сложном

Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
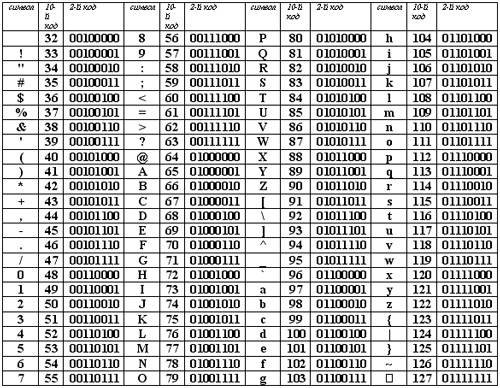
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
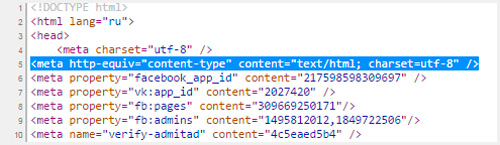
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
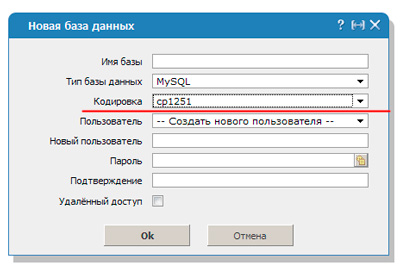
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251»
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.
Что такое windows-1251 кодировка и как ее применять – подробное руководство
Не каждый человек обладает большими познаниями в компьютерной технике.
Что такое windows-1251 кодировка и какую роль играет в работе компьютера предстоит узнать.

Что это такое?
Кодировка 1251 представляет собой совокупность символов, которая составляет восьми-битную систему Windows для русифицированных устройств.
Стоит отметить, что довольное широкое применение она нашла на территории Европы.
Считается одной из самых выгодных кодировок, поскольку в ней присутствует все необходимые символы, которые используются в российской типографии. Все кириллические символы имею алфавитную последовательность.
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются славянские буквы алфавита.
А значит стало возможным использовать компьютеры со следующими языками:
- Русский
- Белорусский
- Украинский
- Сербский
- Болгарский
- Македонский.
Совместно с двумя российскими компаниями «Параграф» и «Диалог», представительства компании Microsoft начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.

Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
В него заложено порядком 90% web-ресурсов. Что касается 1251, то она используется менее, чем в 2%.
UTF-8 против 1251
Вся информация, которая хранится на компьютере, имеет кодированный вид.
Можно предположить, что символ имеет вес порядком 1 байт. 1251 – это разновидность кодировки однобайтовой, а UTF-8 – восьмибайтная.
Отсюда можно сделать вывод, что первый вариант способен к программированию 256 знаков.
Что касается второго варианта, то он представляет большее количество. Кроме того, для этого выделяют большой размер.
Можно сделать вывод, что оба варианта имеют следующие отличия:
- В верхней части необходимо указывать кодировку, которая необходима для использования. В противном случае, вместо обыкновенных символов появляются нечитаемые иероглифы. Используя UTF-8 (которая считается более универсальной кодировкой), все переводы и расшифровки осуществляются в автоматическом режиме
- Вне зависимости от того, на территории какой страны будет загружаться страница, символика останется без изменения. Важно отметить, что местоположение в данном случае не играет абсолютно никакой роли. Главное обращать внимание на языковые серверы, используемые пользователем. Каждый человек обращается к программному обеспечению на родном языке. Для жителей Европы, 1251 будет недоступна в силу использования латиницы. Соответственно можно сделать вывод о том, что русскоязычные сайты не будут открывать в корректном формате. Что касается юникода, то он присутствует в любой ОС
- Второй вид имеет возможность кодировки большего количества символов. На сегодняшний день стоит отметить 6 и 8 байт. Что касается кириллицы, то для ее кодировки достаточно двух байт.
В связи с выше перечисленными отличиями можно сделать вывод о том, что универсальная кодировка более актуальна для использования, чем 1251, поскольку она подойдет только для славянской группы языков.
Для профессиональных программистов и технических специалистов, знание кодировки 1251 является обязательным условием для осуществления полноценной работы.
Чтобы символы можно было запомнить быстро и просто, чаще всего используют следующую таблицу:

Инструкция по восстановлению кодировки
Ситуация, когда в командной строке присутствуют непонятные символы, вопросительные знаки или иероглифы довольна распространенная.
Однако исправить положение возможно самостоятельно, не прибегая к помощи специалистов.
Сразу стоит отметить, что это первый признак того, что в седьмом Windows слетела кодировка 1251.
С восьмой версии активно используют UTF-8.
Для того, чтобы решить задачу максимально быстро, возможно использование команды CHCP 866, но это только временная мера и в полной мере проблему она не решит.
Как правило, реестр используется для основательного решения проблемы:
- Чтобы вызвать командную строку, нажимаем сочетание клавиш Win и R. Пишем regedit, при помощи которого открывается специальный реестр

- Как показано на рисунке, находим соответствующую папку HKEY_CURRENT_USER далее выбираем Console. Далее смотрим какой код задан для страниц (Code Page). В том случае, если там стоит число не 866, что скорее всего так и будет, значит проблема была определена верно

- Исправляем в строке на десятичное значение
- Чтобы править, произошли ли изменения, достаточно открыть и снова вызвать командную строчку.
Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
Существуют и другие аргументы, активно выступающие «ЗА» использование данной системы:
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
Важно отметить, что изначально многие разработчики стали использовать 1251.
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей.
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием.