Стандартная кодировка windows
Отличие utf-8 и windows 1251
Поддержи проект. 
Отличие utf-8 и windows 1251. Рассмотрим, чем отличаются две кодировки «utf-8 и windows 1251» в теории и на практике. И как победить некоторые проблемы для кириллицы в utf-8!?
О разнице между двумя кодировками utf-8 и windows 1251
- О кодировках utf-8 и windows 1251
- Пример вывода текста в кодировках utf-8 латиницы
- Пример вывода текста в кодировках utf-8 кириллицы
- Пример отличия в кодировках utf-8 и windows 1251
- Как перекодировать строку из utf-8 в windows 1251
- Спасшая статья:
- Решения проблемы с кодировкой в CMD. 1 Способ.
- Решения проблемы с кодировкой в CMD. 2 Способ.
- Русский
- Белорусский
- Украинский
- Сербский
- Болгарский
- Македонский.
- В верхней части необходимо указывать кодировку, которая необходима для использования. В противном случае, вместо обыкновенных символов появляются нечитаемые иероглифы. Используя UTF-8 (которая считается более универсальной кодировкой), все переводы и расшифровки осуществляются в автоматическом режиме
- Вне зависимости от того, на территории какой страны будет загружаться страница, символика останется без изменения. Важно отметить, что местоположение в данном случае не играет абсолютно никакой роли. Главное обращать внимание на языковые серверы, используемые пользователем. Каждый человек обращается к программному обеспечению на родном языке. Для жителей Европы, 1251 будет недоступна в силу использования латиницы. Соответственно можно сделать вывод о том, что русскоязычные сайты не будут открывать в корректном формате. Что касается юникода, то он присутствует в любой ОС
- Второй вид имеет возможность кодировки большего количества символов. На сегодняшний день стоит отметить 6 и 8 байт. Что касается кириллицы, то для ее кодировки достаточно двух байт.
- Чтобы вызвать командную строку, нажимаем сочетание клавиш Win и R. Пишем regedit, при помощи которого открывается специальный реестр
- Как показано на рисунке, находим соответствующую папку HKEY_CURRENT_USER далее выбираем Console. Далее смотрим какой код задан для страниц (Code Page). В том случае, если там стоит число не 866, что скорее всего так и будет, значит проблема была определена верно
- Исправляем в строке на десятичное значение
- Чтобы править, произошли ли изменения, достаточно открыть и снова вызвать командную строчку.
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
- Откройте панель управления (для этого можно начать набирать «Панель управления» или «Control Panel» в поиске на панели задач.
- Убедитесь, что в поле «Просмотр» (View by) установлено «Значки» (Icons) и выберите пункт «Региональные стандарты» (Region).

- На вкладке «Дополнительно» (Administrative) в разделе «Язык программ, не поддерживающих Юникод» (Language for non-Unicode programs) нажмите по кнопке «Изменить язык системы» (Change system locale).
- Выберите русский язык, нажмите «Ок» и подтвердите перезагрузку компьютера.
- Нажмите клавиши Win+R на клавиатуре, введите regedit и нажмите Enter, откроется редактор реестра.
- Перейдите к разделу реестраи в правой части пролистайте значения этого раздела до конца.
- Дважды нажмите по параметру ACP, установите значение 1251 (кодовая страница для кириллицы), нажмите Ок и закройте редактор реестра.
- Перезагрузите компьютер (именно перезагрузка, а не завершение работы и включение, в Windows 10 это может иметь значение).
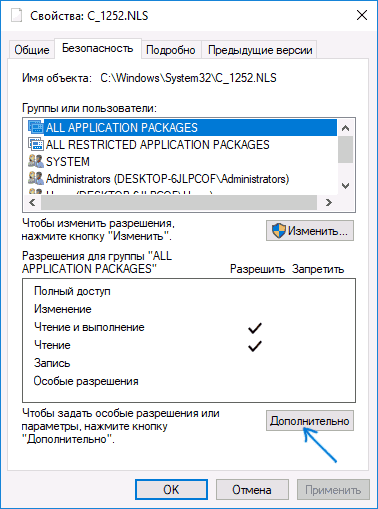
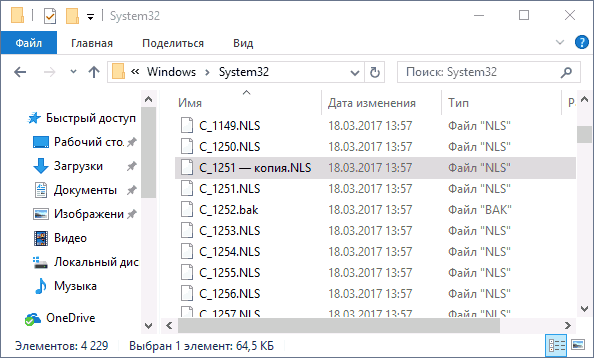
- Зайдите в папку C: Windows System32 и найдите файл c_1252.NLS, нажмите по нему правой кнопкой мыши, выберите пункт «Свойства» и откройте вкладку «Безопасность». На ней нажмите кнопку «Дополнительно».
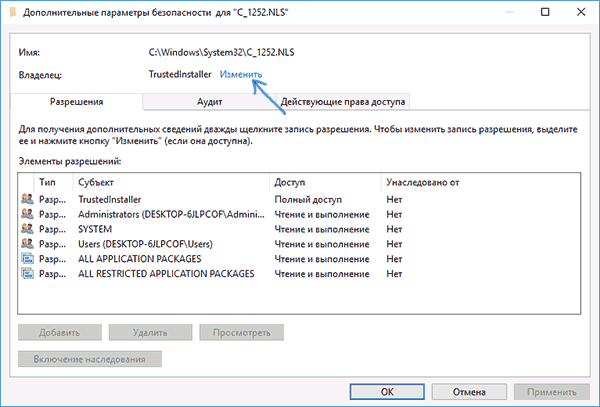
- В поле «Владелец» нажмите «Изменить».
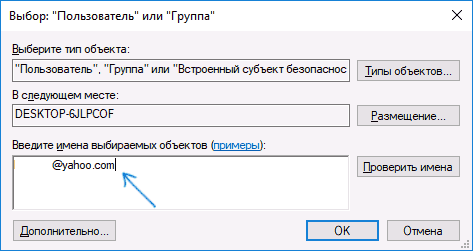
- В поле «Введите имена выбираемых объектов» укажите ваше имя пользователя (с правами администратора). Если в Windows 10 используется учетная запись Майкрософт, вместо имени пользователя укажите адрес электронной почты. Нажмите «Ок» в окне, где указывали пользователя и в следующем (Дополнительные параметры безопасности) окне.
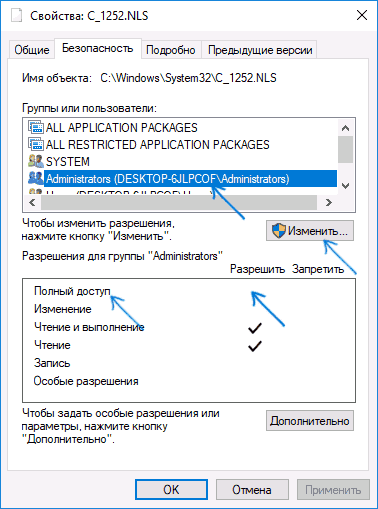
- Вы снова окажетесь на вкладке «Безопасность» в свойствах файла. Нажмите кнопку «Изменить».
- Выберите пункт «Администраторы» (Administrators) и включите полный доступ для них. Нажмите «Ок» и подтвердите изменение разрешений. Нажмите «Ок» в окне свойств файла.
- Переименуйте файл c_1252.NLS (например, измените расширение на .bak, чтобы не потерять этот файл).
- Удерживая клавишу Ctrl, перетащите находящийся там же в C:WindowsSystem32 файл c_1251.NLS (кодовая страница для кириллицы) в другое место этого же окна проводника, чтобы создать копию файла.
- Переименуйте копию файла c_1251.NLS в c_1252.NLS.
- Перезагрузите компьютер.
О кодировках utf-8 и windows 1251
Самое главное. что нас интересует, как и меня — в чем же отличие кодировок utf-8 и windows 1251. И отличается только кириллица!
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка windows 1251
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Пример вывода текста в кодировках utf-8 латиницы
А если вы еще и поняли о чем идет речь, то вы вообще Эйнштейн!  , то и смысла особого вам читать дальше нет.
, то и смысла особого вам читать дальше нет.
А для всех остальных продолжим.
Чем отличается текст в кодировках utf-8 и windows 1251
Теория — это конечно классно и круто, но как обстоит дело на практике!
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И. нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя.
Пусть это будет слово — «Marat!»
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Пример вывода текста в кодировках utf-8 кириллицы
Теперь, проделаем тоже самое со строкой на кириллице:
У нас все таже кодировка utf-8.
Но теперь нам понадобится текст на кириллице:
Пусть это будет слово — «Марат!»
И выведем прямо здесь вот такую конструкцию :
И что мы здесь видим!?
Что количество элементов в строке 10. Если вы читали теорию внимательно, то вот вам показатель того, что одна буква состоит из двух символов, а латиницы это не касается.
Поэтому, и возникают проблемы с текстов в кодировке utf-8 кириллицы, множество функций тупо не работают.
Как пример. как-то я задолбался со strtolower в utf-8 для кириллицы, что решил написать собственную функцию strtolower, чтобы каждый раз не городить этажерку из нескольких функций.
Пример отличия в кодировках utf-8 и windows 1251
Если вы поленились прочитать два верхних пункта, то ещё раз выведем результаты вывода текста на латинице и на кириллице с одним количеством букв.
Результат вывода var_dump(‘Marat’); :
string(5) «Marat»
Результат var_dump(‘Марат’); :
string(10) «Марат»
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции strtolower
Пусть это будет функция str_split и её аналог mb_str_split
chcp 1251 что это значит в батнике
Команда CHCP используется для просмотра или изменения текущей кодовой страницы в окне командной строки Windows. Кодовая страница (Code Page или сокращенно CP) определяет соответствие между двоичным кодом и соответствующим ему символом, отображаемом на экране. Для кодирования текстов на русском языке (то есть букв кириллицы) наиболее широко применяются следующие кодовые страницы:
— Windows-1251, она же Microsoft code page 1251 (CP1251) в операционных системах семейства Windows;
— Кодовая страница CP866, она же IBM code page 866 — в операционных системах семейства DOS, а также в приложениях командной строки Microsoft Windows;
Стандартно, в приложениях командной строки, используется кодовая страница 866 , что соответствует DOS-кодировке. Окно приложения CMD.EXE запускается с установленной кодовой страницей 866 . Изменение кодовой страницы действует только по отношению к текущему сеансу CMD.
Примеры использования команды CHCP:
chcp — отобразить текущую кодовую страницу.
chcp 1251 — установить кодовую страницу, соответствующую Windows-кодировке.
chcp 866 — установить кодовую страницу, соответствующую DOS-кодировке.
При создании командных файлов, необходимо учитывать то обстоятельство, что текст на русском языке должен быть представлен в DOS-кодировке.
Выполняю cmd и в нем set, хочу узнать USERNAME. Но оно показывается в непонятной кодировке.
chcp 866; chcp 1251; chcp 65001 — не помогали.
Оказывается надо в свойствах самого cmd выбрать шрифт Lucida Console. Только так можно получить нормальный текст на русском языке.
Спасшая статья:
Приложение cmd.exe – это командная строка или программная оболочка с текстовым интерфейсом (во загнул ).
Запустить командную строку можно следующим способом: Пуск → Выполнить → вводим в поле команду – cmd и жмем ОК. В итоге откроется рабочее окно программы – c:WINDOWSsystem32cmd.exe. ( рис.1)

Если Вы занялись проблемой кодировки шрифтов в cmd.exe , то как запускать командную строку наверняка уже знаете
Перейдем собственно к проблеме: иногда вместо русских букв при выполнении команд выходит набор непонятных символов ( рис.2).

Первым делом нужно зайти в свойства окна – правой кнопкой щелкнуть по верхней части окна → Свойства → выйдет окно рис.3, здесь в поле Шрифтвыбираем Luc >ОК.

Теперь Вы получили нормальный текст на русском языке. Так же можно поменять текущую кодировку шрифта, для этого используется команда chcp. Набираем эту команду и жмем Enter, в результате получим текущую кодировку для командной строки – рис.4.

Для изменения кодировки так же применим chcp в следующем формате:
Где – это цифровой параметр нужного шрифта, например,
1251 – Windows (кириллица);
Выбирайте на любой вкус. Т.о. что бы изменить кодировку на UTF-8 нужно выполнить команду chcp 65001.

almix
Разработчик Loco, автор статей по веб-разработке на Yii, CodeIgniter, MODx и прочих инструментах. Создатель Team Sense.




Как корректно отобразить Русский текст в CMD. Проблемы с кодировкой могут возникнуть, например, при выполнении Bat файла, когда нужно вывести в консоль русский текст и при других обстоятельствах, о которых речь пойдёт далее.
Рассмотрим пример: когда нужно вывести в консоль Русский текст, скажем «Примет мир». Для этого создадим Bat файл с именем «1.bat». Используйте для этого обычный Блокнот Windows (Notepad.exe) Запишем в него следующие строки!
Для тех, кто не понял или не в курсе, строчки «echo.» я добавил специально, что бы были отступы, от строки «Примет мир»
Теперь запускаем файл 1.bat и результат будет такого вида.

Как видим проблема с кодировкой в cmd на лицо. И произошло это по следующей причине.
Стандартный блокнот Windows сохранил Bat файл в кодировке «1251» а консоль вывела его в кодировки «866». Вот от сюда все проблемы!
Решения проблемы с кодировкой в CMD. 1 Способ.
Для решения проблемы нужно просто использовать текстовой редактор, с помощью которого можно сохранить текст в кодировке «866». Для этих целей прекрасно подходит «Notepad++» (Ссылку для загрузки Вы можете найти в моём Twitter-e).
Скачиваем и устанавливаем на свой компьютер «Notepad++».
После запуска «Notepad++» запишете в документ те же строки, которые мы уже ранние записывали в стандартный блокнот.
Теперь осталось сохранить документ с именем «2.bat» в правильной кодировке. Для этого идём в меню «Кодировки > Кодировки > Кириллица > OEM-866»

и теперь сохраняем файл с именем «2.bat» и запускаем его! Поле запуска результат на лицо.

Как видим, текст на Русском в CMD отобразился, как положено.
Решения проблемы с кодировкой в CMD. 2 Способ.
Теперь рассмотрим ещё одну ситуацию, когда могут возникнуть проблемы с кодировкой в CMD.
Допустим, ситуация требует сохранить результат выполнения той или иной команды в обычный «TXT» файл. В приделах этого поста возьмём для примера команду «HELP».
Задача : Сохранить справку CMD в файл «HelpCMD.txt. Для этого создайте Bat файл и запишите в него следующие строки.
После выполнения Bat файла в корне диска «C:» появится файл «HelpCMD.txt» и вместо справки получится вот что:

Естественно, такой вариант не кому не понравится и что бы сохранить справку в понятном для человека виде, допишите в Bat файл строку.
Теперь содержимое кода будет такое.
После выполнения «Батника» результат будет такой:

Вот так на много лучше, правда?
Пожалуй, на этом я закончу пост. Добавить больше нечего. Если у Вас имеются какие-то соображения по данной теме, буду рад Вашему комментарию к посту.
Дополнительно из комментариев то Garric
Автор очень хорошо описал принцип. ! Но это неудобно.
Нужно бы добавить. Если автор добавит это в статью то это будет Good.
Создаём файл .reg следующего содержания:
——
Windows Registry Editor Version 5.00
Выбор кодировки текста при открытии и сохранении файлов
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Нажмите кнопку Параметры.
Нажмите кнопку Дополнительно.
Перейдите к разделу Общие и установите флажок Подтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Нажмите кнопку Пуск и выберите пункт Панель управления.
Выполните одно из указанных ниже действий.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В Windows Vista
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл.
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Нажмите кнопку Сохранить.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7)
Стандартный шрифт для стиля «Обычный» локализованной версии Word
Windows 1256, ASMO 708
Китайская (упрощенное письмо)
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ
Китайская (традиционное письмо)
BIG5, EUC-TW, ISO-2022-TW
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866
Английская, западноевропейская и другие, основанные на латинице
Что такое windows-1251 кодировка и как ее применять – подробное руководство
Не каждый человек обладает большими познаниями в компьютерной технике.
Что такое windows-1251 кодировка и какую роль играет в работе компьютера предстоит узнать.

Что это такое?
Кодировка 1251 представляет собой совокупность символов, которая составляет восьми-битную систему Windows для русифицированных устройств.
Стоит отметить, что довольное широкое применение она нашла на территории Европы.
Считается одной из самых выгодных кодировок, поскольку в ней присутствует все необходимые символы, которые используются в российской типографии. Все кириллические символы имею алфавитную последовательность.
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются славянские буквы алфавита.
А значит стало возможным использовать компьютеры со следующими языками:
Совместно с двумя российскими компаниями «Параграф» и «Диалог», представительства компании Microsoft начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.

Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
В него заложено порядком 90% web-ресурсов. Что касается 1251, то она используется менее, чем в 2%.
UTF-8 против 1251
Вся информация, которая хранится на компьютере, имеет кодированный вид.
Можно предположить, что символ имеет вес порядком 1 байт. 1251 – это разновидность кодировки однобайтовой, а UTF-8 – восьмибайтная.
Отсюда можно сделать вывод, что первый вариант способен к программированию 256 знаков.
Что касается второго варианта, то он представляет большее количество. Кроме того, для этого выделяют большой размер.
Можно сделать вывод, что оба варианта имеют следующие отличия:
В связи с выше перечисленными отличиями можно сделать вывод о том, что универсальная кодировка более актуальна для использования, чем 1251, поскольку она подойдет только для славянской группы языков.
Для профессиональных программистов и технических специалистов, знание кодировки 1251 является обязательным условием для осуществления полноценной работы.
Чтобы символы можно было запомнить быстро и просто, чаще всего используют следующую таблицу:

Инструкция по восстановлению кодировки
Ситуация, когда в командной строке присутствуют непонятные символы, вопросительные знаки или иероглифы довольна распространенная.
Однако исправить положение возможно самостоятельно, не прибегая к помощи специалистов.
Сразу стоит отметить, что это первый признак того, что в седьмом Windows слетела кодировка 1251.
С восьмой версии активно используют UTF-8.
Для того, чтобы решить задачу максимально быстро, возможно использование команды CHCP 866, но это только временная мера и в полной мере проблему она не решит.
Как правило, реестр используется для основательного решения проблемы:


Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
Существуют и другие аргументы, активно выступающие «ЗА» использование данной системы:
Важно отметить, что изначально многие разработчики стали использовать 1251.
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей.
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием.
Как исправить отображение кириллицы или кракозябры в Windows 10
Одна из возможных проблем, с которыми можно столкнуться после установки Windows 10 — кракозябры вместо русских букв в интерфейсе программ, а также в документах. Чаще неправильное отображение кириллицы встречается в изначально англоязычных и не совсем лицензионных версиях системы, но бывают и исключения.
В этой инструкции — о том, как исправить «кракозябры» (или иероглифы), а точнее — отображение кириллицы в Windows 10 несколькими способами. Возможно, также будет полезным: Как установить и включить русский язык интерфейса в Windows 10 (для систем на английском и других языках).
Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
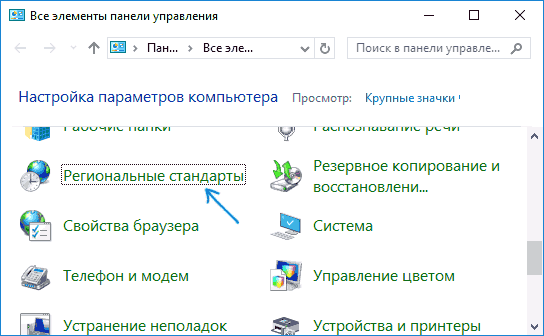
Самый простой и чаще всего работающий способ убрать кракозябры и вернуть русские буквы в Windows 10 — исправить некоторые неправильные настройки в параметрах системы.
Для этого потребуется выполнить следующие шаги (примечание: привожу также названия нужных пунктов на английском, так как иногда необходимость исправить кириллицу возникает в англоязычных версиях системы без нужды менять язык интерфейса).
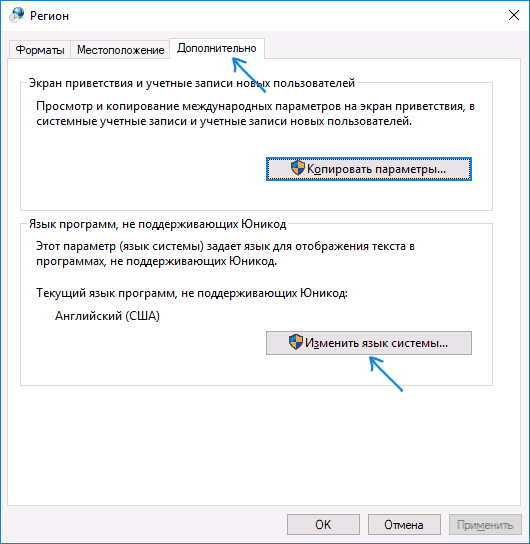
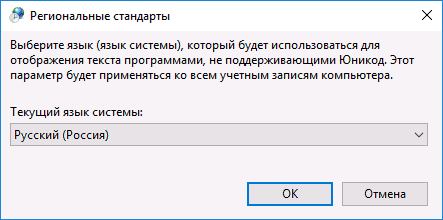
После перезагрузки проверьте, была ли решена проблема с отображением русских букв в интерфейсе программ и (или) документах — обычно, кракозябры бывают исправлены после этих простых действий.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
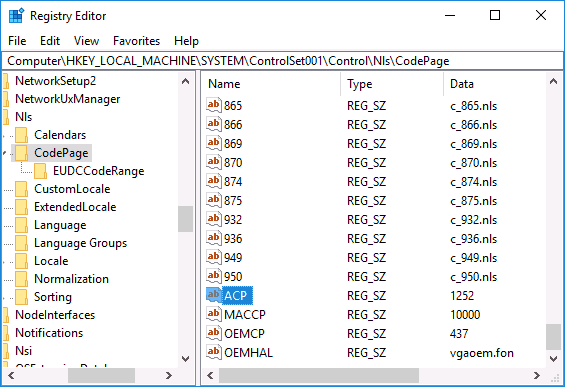
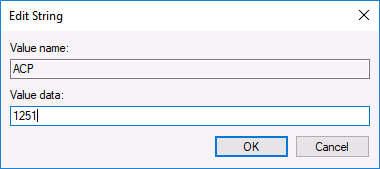
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
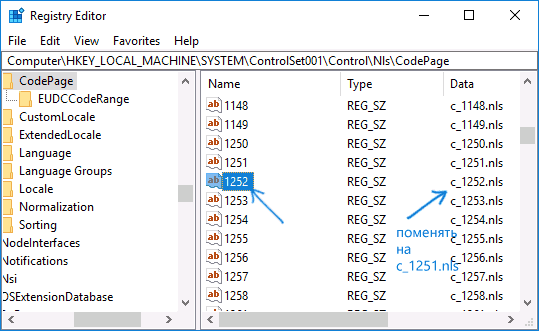
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C: Windows System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.